https://arxiv.org/abs/2301.12597
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from o
arxiv.org
Abstract
본 논문은 BLIP-2라는 효율적인 사전 학습 전략을 제안하며 사전 학습된 off-the-shelf 이미지 인코더와 대규모 언어 모델을 사용하여 비전-언어 사전 학습을 bootstrappin g 한다.
BLIP-2는 2단계로 이루어진 Querying Transformer를 사용한다. 첫 번째 스테이지는 frozen image encoder에서 비전-언어 표현을 학습한다. 두 번째 스테이지에서는 frozen language model에서 비전-언어 생성을 학습한다.
Introduction
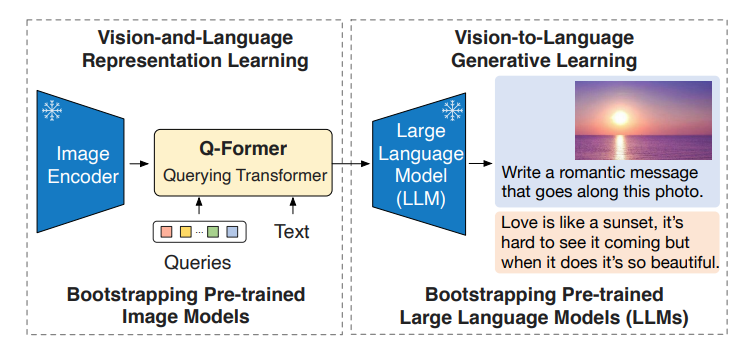
본 논문은 BLIP-2라는 계산 효율적인 VLP 방법을 제안하며, 이를 통해 사전 학습된 이미지 및 언어 모델을 활용한다. 사전 학습된 이미지 및 언어 모델을 사용하며 고품질의 시각적 표현을 얻으며 LLMs의 언어 생성 및 제로샷 전이 능력을 얻는다. 계산 효율적을 위해서 unimodal을 frozen 상태로 유지하여 계산 비용을 줄이고 모델의 파라미터 catastrophic forgetting 문제를 방지한다.
BLIP-2는 Querying Transformer (Q-Former)를 사용한다. 경량화된 Transformer로 학습 가능한 쿼리 벡터(query vector)를 활용해 동결된 이미지 인코더로부터 시각적 특징을 추출한다. 이미지와 언어 간의 bottleneck 역할을 하며 간극을 연결한다. 이후 frozen LLM을 활용해 필요한 시각 정보를 텍스트로 추출한다.
- 비전-언어 표현 학습
- Q-Former가 text와 관련된 visual 표현을 학습
- 비전-언어 생성 학습
- Q-Former의 output을 frozen된 LLM과 연결하여 해석할 수 있도록 학습
BLIP-2의 주요 장점
- 효율적 : frozen된 사전 학습 모델을 사용. Q-Former 사전 학습을 통해 모달리티 간 간극 극복
- 제로샷
- 계산 효율성 : frozen된 사전 학습과, 경량화된 Q-Former를 존재하는 sota 모델보다 계산이 효율적이다.
Method

- Q-Former: 이미지와 언어 간의 모달리티 간극을 연결하기 위해 제안된 가볍고 효율적인 트랜스포머 모듈.
- 2단계 사전 학습 전략:
- 비전-언어 표현 학습 (Representation Learning): 동결된 이미지 인코더 사용
- 비전-언어 생성 학습 (Generative Learning): 동결된 대규모 언어 모델(LLM) 사용
Model Architecture
Q-Former는 동결된 이미지 인코더와 언어 모델(LLM) 간의 간극을 연결하기 위한 학습 가능한 모듈이다. 고정된 수의 출력 feature를 이미지 인코더에서 추출한다.
- Image transformer
- frozen image encoder와 상호작용하여 시각적 특징 추출
- 학습 가능한 query embedding을 input으로 사용
- query는 self-attention layer으로 상호작용하며 이미지 특징과는 cross-attention layer으로 상호작용
- Text transformer
- 텍스트 인코더와 텍스트 디코더 모두 작동
- 동일한 self-attention layer를 사용해 쿼리와 텍스트 간 상호작용
Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
표현 학습 단계에서는 Q-Former를 frozen 이미지 인코더와 연결하여 이미지-텍스트 쌍을 사용해 사전 학습을 수행한다. 이 과정에서 query가 텍스트와 관련된 가장 유용한 시각적 표현을 추출하도록 학습한다. BLIP에서 영감을 받아 세 가지 사전 학습 목적을 함께 최적화한다.
Image-Text Contrastive Learning (ITC)
ITC는 이미지 표현과 텍스트 표현을 정렬하여 상호 정보를 최대화하는 것을 목표로 한다.
- 방법 : 이미지 트랜스포머의 출력인 쿼리 표현 Z와 텍스트 트랜스포머의 출력인 텍스트 표현 t를 정렬
- 계산 : 각 쿼리의 출력과 t 의 유사성을 계산한 후, 가장 높은 값을 이미지-텍스트 유사도로 선택
- 마스킹 : 단일 모달 self-attention 마스크를 적용
Image-grounded Text Generation (ITG)
ITG 손실은 Q-Former가 이미지를 조건으로 텍스트를 생성하도록 학습한다.
- 정보 전달: Q-Former는 쿼리를 통해 필요한 시각 정보를 추출한 뒤, 이를 자기-어텐션(self-attention) 레이어를 통해 텍스트 토큰에 전달
- 마스킹: UniLM과 유사한 멀티모달 인과적 자기-어텐션 마스크를 사용 (쿼리 : 상호작용 가능하지만 텍스트 토큰 볼 수 없음 / 텍스트 토큰 : 모든 쿼리와 이전 텍스트 토큰을 볼 수 있음)
- 디코딩 신호: [CLS] 토큰 대신 새로운 [DEC] 토큰을 첫 텍스트 토큰으로 사용하여 디코딩 작업을 신호화
Image-Text Matching (ITM)
ITM은 이미지와 텍스트 표현 간의 세부 정렬(fine-grained alignment)을 학습하는 이진 분류 작업이다.
- 작업: 모델은 이미지-텍스트 쌍이 양성인지 음성인지 예측
- 마스킹: 모든 쿼리와 텍스트가 서로를 볼 수 있도록 양방향(self-attention) 마스크를 사용
Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
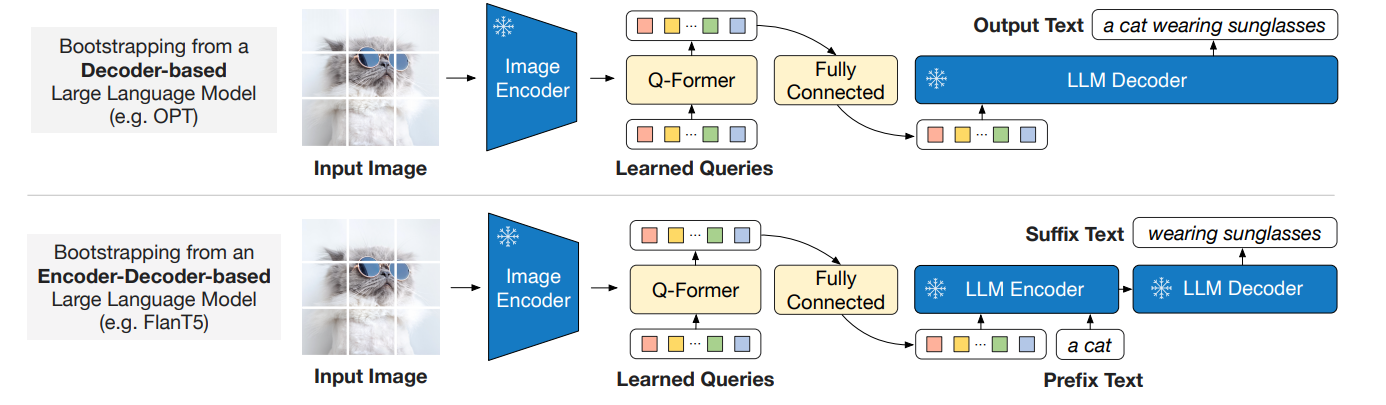
Generative learning 단계에서는 Q-Former를 frozen된 LLM과 연결하여 생성적 언어 능력을 활용한다.
Q-Former의 출력 쿼리 임베딩(Z)은 완전 연결층(FC)을 통해 LLM의 텍스트 임베딩 차원과 일치하도록 선형 변환된다. 변현된 쿼리 임베딩은 텍스트 임베딩 앞에 추가되며 소프트 비주얼 프롬프트 역할을 하며, Q-Former에서 추출한 시각적 표현에 따라 LLM을 조정한다. Q-Former는 시각적 정보를 텍스트와 관련된 중요한 정보만 남기고 불필요한 정보를 제거하여 LLM에 전달하며 catastrophic forgetting 문제를 완화한다.
LLM은 decoder-based와 encoder-decoder-based LLM이 존재한다.
- Decoder-based LLM
- language modeling loss를 사용하여 LLM이 Q-Former에서 추출한 시각적 표현을 조건으로 텍스트를 생성하도록 학습
- Encoder-decoder-based LLM
- 프리픽스 언어 모델링 손실(prefix language modeling loss)을 사용
- 텍스트를 두 부분으로 나누어, 텍스트의 앞부분(프리픽스)과 시각적 표현을 LLM의 인코더 입력으로 제공
- 텍스트의 뒷부분(서픽스)은 LLM 디코더의 생성 목표로 사용
Model Pre-training
Pre-training data
BLIP와 동일한 사전 학습 데이터셋을 사용하며, 총 1.29억 개의 이미지가 포함된다. 웹 이미지를 위한 합성 캡션은 CapFilt 방법을 사용하여 생성된다.
Pre-trained image encoder and LLM
이미지 인코더 (1) ViT-L/14 (CLIP) (2) ViT-g (EVA-CLIP)
언어 모델 (1) OPT 모델군 (디코더 기반 LLM) (2) Flan T5 모델군 (인코더-디코더 기반 LLM)
