https://arxiv.org/abs/2408.16219
Training-free Video Temporal Grounding using Large-scale Pre-trained Models
Video temporal grounding aims to identify video segments within untrimmed videos that are most relevant to a given natural language query. Existing video temporal localization models rely on specific datasets for training and have high data collection cost
arxiv.org
Abstract
Video Temporal Grounding은 주어진 자연어 query에 가장 관련 있는 비디오 구간을 식별하는 작업이다. 기존의 모델은 특정 데이터셋에 의존하여 학습되므로 일반화 성능이 낮고, 데이터 수집 비용이 높은 문제가 있다. 따라서 본 논문에서는 Training-Free Video Temporal Grounding 모델을 제안한다. 이 접근번은 VLM, LLM을 사용해 별도의 학습 없이도 Video Temporal Grounding을 수행한다.
기존의 VLM은 (1) 동일한 비디오 내에서 여러 이벤트 간의 경계를 파악하고 시간적 경계를 구별, (2) 이벤트 간의 동적인 변화에 대한 이해를 수행하기 위해 노력한다. 본 논문에서는 LLM을 사용해 (1) query 안의 sub-event를 분석하여 시간적 순서 및 관계를 파악, (2) sub-event를 동적 전환 부분 dynamic transition 과 정적 상태 부분 static status로 나누고 VLM을 이용해 이벤트와 쿼리 간 관련성을 평가, (3) LLM이 제공한 하위 이벤트의 순서와 관계를 기반으로 VLM이 생성한 상위-k 제안을 필터링 및 통합한다.
TFVTG는 학습 없이 Charades-STA와 ActivityNet Captions 데이터셋에서 최고 성능을 기록했으며 cross-dataset 및 OOD 설정에서 높은 일반화 능력을 입증했다.

Introduction
TFVTG (Training-Free Video Temporal Grounding)은 사전 학습된 대규모 언어 모델(LLM)과 비전-언어 모델(VLM)을 활용하여 학습 없이 시간적 그라운딩을 수행한다. 기존의 간단한 방법으로는 비디오 내 제안된 구간을 열거하고 VLM으로 쿼리 간의 정렬을 평가한다. 하지만 (1) 단일 이미지로 pre-trained 되어 다듬어지지 않은 비디오에서 시간 경계에 대한 이해가 어렵다. VLM은 multiple sequential events와 temporal relationships를 이해해야한다. (2) contrastive learning으로 학습되어 이벤트 시작 동작 부분을 간과한다. 가장 두드러진 시각적 cue를 text랑 연관지으려고 하여 dynamic transitions과 이벤트 경계 localize가 어렵다.
따라서 LLM을 결합하여 해당 문제를 해결한다. LLM으로 쿼리를 분석해 sub-event로 나누고 각 이벤트의 순서와 관계를 추론한다. 또한 비디오의 시간적 경계를 이해하지 못하는 VLM은 동적 전환(Dynamic Transition) 및 정적 상태(Static Status)를 명시적 고려한다.
- 동적 구간(Dynamic Segment): 이벤트 시작부에서의 비디오-텍스트 유사도 변화율(rate of similarity change)을 측정
- 정적 구간(Static Segment): 이벤트 완료 후, 비디오-텍스트 평균 유사도를 평가하고 외부 유사도와 비교
ex) "사람이 사진을 벽에 걸었다"는 쿼리를 처리할 때
- 동적 구간: 사람이 사진을 점차적으로 들어 올리고 벽에 접근하는 장면
- 정적 구간: 사진이 이미 벽에 걸린 후 사람이 카메라를 바라보는 장면
또한 좋은 proposal은 동적 구간에서 유사도가 크게 증가하고, 정적 구간에서는 내부 유사도가 높으며 외부 유사도는 낮은 특징을 보여야 한다. 후에 각 이벤트 proposal에 대해 동적 점수와 정적 점수를 합산해 최종 점수를 계산한다.
- 동적 점수: 동적 구간에서 유사도 변화율 평가
- 정적 점수: 정적 구간 내부와 외부 유사도의 차이를 평가
최종적으로, 점수가 가장 높은 후보를 선택해 하위 이벤트를 로컬라이즈하고 LLM이 제공한 이벤트 간 순서와 관계 정보를 바탕으로 결과를 필터링하고 통합해 최종 예측값을 생성한다.
즉,
(1) LLM 사용해 이벤트를 sub-event로 세분화하고 관계를 추론, VLM은 sub-event를 비디오에서 정확히 로컬라이즈
(2) 동적/정적 구간 모델
(3) 제로샷 학습 및 일반화 성능 향상
Method
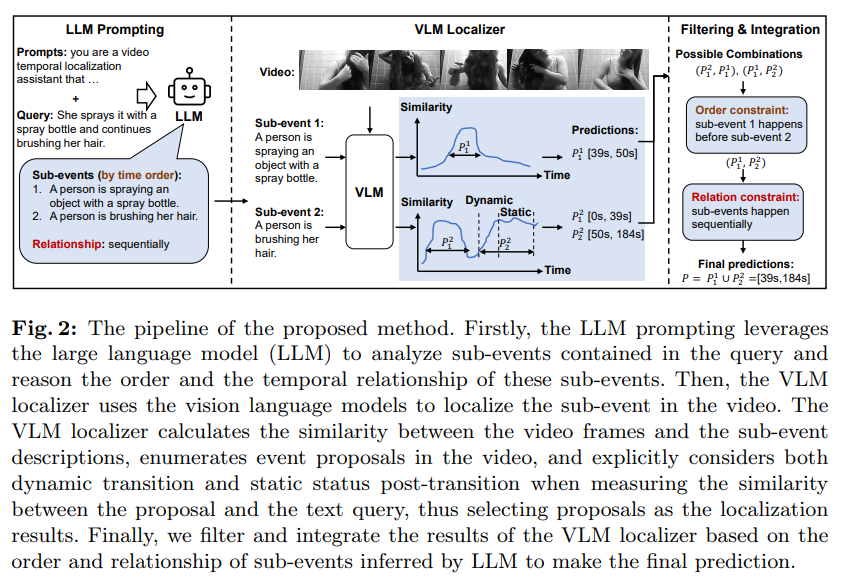
LLM Prompt
LLM prompt를 사용해 query text를 분석한다.
- Reasoning : user의 쿼리를 분석하고 sub-event가 있는지 확인
- Order of sub-events : sub-event를 시간 순서에 따라 제공
- Relationships between sub-events : 이벤트 간 관계 (Single event / Simultaneously / Sequentially) 를 고려
- Textual descriptions : 각 하위 이벤트에 대한 설명을 생성
Grounding with Vison Language Model
VLM(Video-Language Model)의 멀티모달 정렬 능력을 활용해 비디오 내 하위 이벤트를 로컬라이즈하는 방법을 제안한다. BLIP-2 Q-Former를 로컬라이저로 선택하여, 텍스트와 비디오 간 유사도를 기반으로 이벤트를 추적한다. 또한 동적 점수(Dynamic Score)와 정적 점수(Static Score)를 조합해 이벤트의 시작과 끝을 정밀하게 결정한다.
1. 텍스트-비디오 특징 추출
텍스트 설명 $c$와 비디오 프레임 $v_1, \dots, v_N$에 대해 텍스트와 비전 공간이 정렬되어 있으므로, 코사인 유사도를 사용해 관련성을 측정한다
- 텍스트 특징: $f_c \in \mathbb{R}^D$
- 비전 특징: $F_v = [f_{v1}, \dots, f_{vN}] \in \mathbb{R}^{N \times D}$

2. 단순 열거 방식의 문제
평균 유사도가 높은 구간만 선택하면, 모델이 이벤트의 동적 전환을 무시하고 정적 상태만 예측하는 경향이 있다. 단순 베이스라인에서 시작 시간보다 더 늦은 타임스탬프를 예측하는 비율이 56.1%로 확인되었다. 따라서 동적 전환(Dynamic Transition) 및 정적 상태(Static Status)를 명시적 고려한다.
- ex) "a person sits down" → 사람이 앉는 동적 과정을 무시하고 이미 앉아 있는 상태를 선택
Dynamic Scoring
동적 부분에서는 비디오의 내용이 다른 이벤트에서 타겟 이벤트로 전환되는 과정을 잡아내야 한다.
→ 이 구간에서 비디오-쿼리 간의 유사도가 빠르게 증가하는 것을 확인해야 한다.
Step 1: 가우시안 필터 적용
- 비디오의 흔들림(잡음) 같은 불필요한 영향을 제거하기 위해 가우시안 필터를 적용해 유사도를 부드럽게 만듦
- 필터 적용 결과: $\hat{S} = G(S)$
Step 2: 유사도 변화량 계산
- 필터링된 유사도의 변화량(차분값) 계산: $D_i = \hat{S}_i - \hat{S}_{i-1}$
- 각 프레임에서 이전 프레임과 비교해 얼마나 유사도가 증가했는지 측정
Step 3: 동적 구간 판단 및 점수 계산
- 구간 $(i, k)$에서 모든 변화량 $D_i$가 임계값 $\delta$를 넘으면, 이 구간을 동적 구간으로 판단
- $D_i > \delta$인 모든 값을 더해 동적 점수로 사용
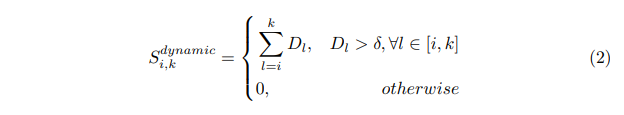
Static Scoring
정적 부분에서는 이벤트 내에서 유사도가 높고, 이벤트 외부에서는 유사도가 낮아야 한다.
Step 1: 구간 내 평균 유사도 계산
- 구간 $(k, j)$ 내에서의 평균 유사도 계산
Step 2: 구간 외 평균 유사도 계산
- 구간 외부 프레임들의 평균 유사도 계산
Step 3: 차이를 점수화
- 내부 평균과 외부 평균의 차이를 계산하여 정적 점수로 사용

동적 & 정적 점수를 활용한 로컬라이제이션
동적 점수와 정적 점수를 조합해 비디오에서 타겟 이벤트의 정확한 위치를 찾는다. 제안된 구간 에서 전환점 $k$를 찾고 각 구간의 동적 점수와 정적 점수를 계산하고 합산한다. $S_final$ 점수가 가장 높은 상위 $k$개의 구간을 선택해 타겟 이벤트를 로컬라이제이션한다.

Prediction Filtering and Integration
VLM 로컬라이저는 각 하위 이벤트 설명에 대해 상위 $k$개의 예측을 반환한다. LLM에서 추론한 하위 이벤트의 순서 및 관계를 반영해 예측을 필터링하고 통합한다.
- 순서 제약 조건 적용
- ex) 하위 이벤트 $P_i$가 $P_j$보다 먼저 발생해야 한다면, $s_i > e_j$인 조합은 제외
- 최적의 조합 선택
- $S_{\text{final}}$ 점수 합이 가장 높은 조합을 선택
- 관계 기반 통합
- 하위 이벤트가 동시에 발생해야 한다면 교집합을 사용
- 그렇지 않으면 합집합을 사용
Expermients

- Charades-STA에서 R@0.5 기준 VTG-GPT 대비 6.29% 향상
- 비지도 학습 방식 대비 9.27% 우위
- 지도 학습 방식이 성능 저하를 겪는 반면, 제안된 방법은 분포에 의존하지 않아 성능 유지
- Charades-STA R@0.5: 49.97% (최고 기록)
Conclusion
LLM과 VLM의 능력을 활용하여 특정 비디오 시간적 로컬라이제이션 데이터셋 없이 작업을 수행한다. LLM은 쿼리에서 다중 서브 이벤트를 분석하고, 이들의 시간적 순서와 관계를 추론한다. 이후 VLM은 비디오에서 서브 이벤트를 로컬라이즈하며, LLM이 제공한 순서와 관계를 기반으로 예측을 통합한다.
이러한 방법으로 Charades-STA와 ActivityNet Captions 데이터셋의 제로샷 설정에서 최고 성능을 달성하였으며, 크로스 데이터셋 및 OOD 환경에서도 우수한 일반화 성능을 입증하였다. 다만, LLM이 이벤트 순서와 관계를 추론하는 과정에서 항상 신뢰할 수 있는 결과를 제공하지 못해 성능 저하의 원인이 될 수 있다.