https://arxiv.org/abs/2405.15587
Composed Image Retrieval for Remote Sensing
This work introduces composed image retrieval to remote sensing. It allows to query a large image archive by image examples alternated by a textual description, enriching the descriptive power over unimodal queries, either visual or textual. Various attrib
arxiv.org

Abstract
본 논문은 composed image retrieval을 remote sensing에 도입한다. 이를 통해 시각적 또는 텍스트 기반의 단일 쿼리 대신, 텍스트 설명으로 된 이미지 예제를 사용하여 대규모 이미지 아카이브를 검색할 수 있다. 이미지-이미지 및 텍스트-이미지 유사성을 융합하는 새로운 방법이 도입되었으며 이를 통해 비전-언어 모델이 충분한 기술적 표현력을 가지고 있어 추가적인 학습 단계나 훈련 데이터가 필요하지 않음을 보인다.
Introduction
RSIR(Remote sensing image retrieval) 방법은 사용자가 자신의 특정 요구 사항을 완전히 표현하지 못한다. 이상적으로 사용자가 이미지 기반 쿼리와 함께 세부적인 수정 사항이나 사양을 표현할 수 있는 시스템이 필요하다. CIR(Composed Image Retrieval)은 이미지와 텍스트를 통합하여 검색 쿼리를 구성하여 쿼리 이미지와 시각적으로 유사할 뿐만 아니라 동반된 텍스트의 세부 사항에도 부합하는 이미지를 검색하도록 설계되었다.
본 논문에서는 CIR이 RS 분야에 도입되며 제공하는 가능성을 평가한다. 사용자는 쿼리 이미지와 함께 텍스트를 조합해 색상, 문맥, 밀도, 존재 여부, 수량, 형태, 크기, 질감 등 하나 이상의 클래스와 관련된 수정을 지정할 수 있다.
즉,
(1) CIR 분야를 RS 분야에 도입
(2) trainig-free WEICOM 제안하여 검색 요구에 따라 이미지 중심 또는 텍스트 중심 결과를 조정
(3) WEICOM의 평가와 SOTA 제시
Related Work
Remote Sensing Image Retrieval
초기 RSIR 방법은 수작업으로 설계된 저수준 시각적 특징에 중점을 두었고, 딥러닝의 등장으로 단일 소스(single-label) 검색에 활용되었다. RSIR 방법은 쿼리 이미지와 검색된 이미지가 동일한 출처에서 비롯되었는지 여부에 따라 단일 소스(unisource)와 교차 소스(cross-source)로 분류된다.
단일 소스의 경우 이미지를 하나의 라벨(single-label)로 검색할 것인지 다중 라벨(multi-label)로 검색할 것인지에 따라 세부적으로 나뉜다. 교차 소스는 쿼리 이미지와 검색된 이미지가 서로 다른 출처에서 비롯된 경우를 말한다. 여기서 소스는 다른 모달리티, 시점, 센서가 될 수 있다. 본 연구는 쿼리 이미지와 텍스트를 결합함으로써 RSIR에서 사용자 의도 표현을 향상시키고 중요한 공백을 메운다.
Composed Image Retrieval
사용자 의도를 가장 정확하고 유연하게 표현할 수 있는 방법은 이미지와 텍스트를 결합한 쿼리이다. CIR은 쿼리 이미지와 시각적으로 유사할 뿐만 아니라 쿼리 텍스트의 세부 사항에 맞게 변경된 이미지를 검색하는 것을 목표로 한다.
Method
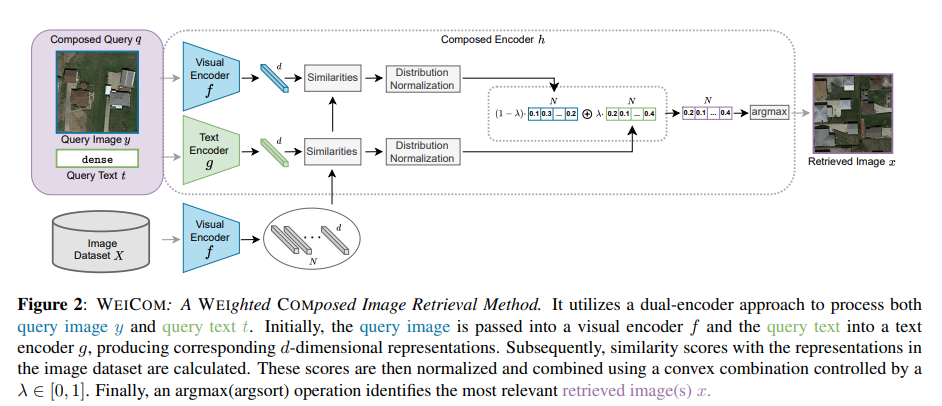
Problem formulation
쿼리는 시각적 요소인 쿼리 이미지와 텍스트 요소인 쿼리 텍스트로 구성된다.
- 쿼리 이미지를 $y$라 하고, 해당 이미지의 클래스는 $C_y$, 이미지에 나타난 클래스의 속성은 $A_y$라 정의
- 사용자가 찾고자 하는 이미지와 유사한 참조 이미지
- 쿼리 텍스트를 $t$라 하며, 이는 수정된 목표 속성 $A_t$를 나타냄
- 쿼리 이미지에서 변경하고 싶은 특성을 설명하는 텍스트
- 합성 쿼리는 $q = (y, t)$로 표현
주어진 이미지 데이터셋 $X$에서 우리의 목표는 쿼리 이미지의 클래스 $C_y$를 공유하며 텍스트 쿼리 $t$로 정의된 속성 $A_t$를 가지는 이미지를 검색하는 것이다. 다시 말해서 주어진 이미지 데이터셋에서 다음 조건을 만족하는 이미지를 찾는 것이다.
(1) 쿼리 이미지와 같은 클래스($C_y$)에 속함
(2) 쿼리 텍스트에서 요청한 속성($A_t$)을 가짐
검색 과정은 합성 유사도 $s(q,x) ∈ R$를 기준으로 데이터셋의 이미지 $x \in X$를 쿼리와의 유사성 순위에 따라 정렬한다. 검색을 위해서는 사전 학습된 VLM을 사용하고, 모델은 두 가지 인코더 (1) 시각적 인코더 $f$ (2) 텍스트 인코더 $g$로 구성된다. 인코더는 이미지와 텍스트를 동일한 차원($d$)의 벡터 공간으로 변환한다.
- 쿼리 이미지 $y$의 시각적 임베딩 : $$ v_y = f(y) \in \mathbb{R}^d $$
- 텍스트 쿼리 $t$의 텍스트 임베딩 : $$ v_t = g(t) \in \mathbb{R}^d $$
- 데이터셋 이미지 $x \in X$의 임베딩 : $$ v_x = f(x) \in \mathbb{R}^d $$
모든 임베딩은 $l_2$ 정규화가 적용된다.
Baselines
unimodal은 단일 유형의 쿼리만 사용해 유사도를 측정한다. 이미지와 텍스트의 정보를 모두 통합한 최종 유사도를 표현할 수 없으므로 성능이 낮다.
multimodal은 두 단일 모달 접근법을 결합하여 유사도를 평균화한다.
$$ s_a(q,x) = \frac{s_g(q,x) + s_f(q,x)}{2} $$
$g(t)$와 $f(y)$를 평균화한 뒤 한 번만 유사도를 계산하는 것과 동일하다. 하지만 모달리티에서 유래한 특성 간 유사도가 교차 모달 특징 간 유사도보다 훨씬 크게 나타나는 경향이 있어 이미지 쿼리에 편향된 결과를 초래할 수 있다.
WEICOM
제안하는 WEICOM 방법에서는 이미지 쿼리의 유사도 $s_f(q, x)$와 텍스트 쿼리의 유사도 $s_g(q, x)$를 데이터베이스와 비교하여 계산한다. 이후, 두 모달리티의 기여가 동일한 출발점을 가지도록 유사도 정규화를 수행하며, 이를 $s'_f(q, x)$와 $s'_g(q, x)$로 나타낸다. 마지막으로, 모달리티 제어 매개변수 $\lambda$를 사용하여 두 유사도 집합의 가중 평균을 계산한다.
$$s_{WC}(q, x) = \lambda s'_g(q, x) + (1 - \lambda)s'_f(q, x)$$
Similarity Normalization
이미지와 텍스트 쿼리가 검색에 동일하게 기여하도록 하기 위해, 유사도를 데이터베이스와 함께 정규화한다. 먼저, 유사도 점수의 경험적 분포를 표준 정규 분포(평균 0, 표준 편차 1)로 변환한다. 이후 표준 정규 분포의 누적 분포 함수(CDF)를 표준화된 데이터에 적용하여 0과 1 사이의 값을 생성한다. 표준화된 데이터가 정규 분포를 따르는 것으로 가정하면, 이 변환은 데이터가 균등 분포를 근사하도록 만든다. 이 과정을 통해, 텍스트와 이미지의 유사도 점수는 동일한 스케일과 분포를 가지게 된다.
The modality control parameter λ
정규화된 유사도를 기반으로, $\lambda$ 매개변수를 사용하여 각 모달리티의 영향을 제어할 수 있다. 여기서 $\lambda = 0$은 이미지 기반 검색, $\lambda = 1$은 텍스트 기반 검색, $\lambda = 0.5$는 이미지와 텍스트가 동일하게 기여하는 경우를 나타낸다.
Experiments
PatternNet 기반 고해상도 원격 감지 이미지 검색 데이터셋인 PATTERNCOM을 사용한다. 쿼리 이미지와 해당 클래스의 속성을 정의하는 쿼리 텍스트 결합한다.
ex) “수영장” + “모양” 속성 → “직사각형”, “타원형”, “콩팥 모양”

WEICOM과 RemoteCLIP을 사용하여 PATTERNCOM에서 수행된 복합 이미지 검색(composed image retrieval) 결과를 제시한다. "모양" 속성은 "타원형(oval)" 또는 "직사각형(rectangular)"과 같은 다양한 값을 포함한다.

WEICOM이 단일 모달(unimodal) 모델(“Text”, “Image”) 및 다중 모달(multimodal) 모델(“Text & Image”) 대비 큰 성능 향상을 보인다.
Ablation study
모달리티 제어 파라미터 $\lambda$의 영향
$\lambda$는 이미지와 텍스트 간의 기여도를 조정하는 파라미터로, $\lambda=0$은 이미지만 사용, $\lambda=1$은 텍스트만 사용한다.

RemoteCLIP은 $\lambda=0.6$에서 평균 mAP가 최고(30.2%)로 나타났으며, 이를 WEICOM의 기본 설정으로 선택한다. CLIP 기반은 $\lambda=0.3$에서 평균 mAP가 최고(27.9%)로 나타났다.
Conclusion
검색 쿼리에 이미지와 텍스트를 통합하며, 이를 지원하기 위해 PATTERNCOM이라는 벤치마크 데이터셋을 제공한다. 색상(color)이나 모양(shape)과 같은 속성을 수정하는 활용 사례를 통해 이 작업의 다양성을 입증하였고, 모달리티 제어 파라미터 $\lambda$를 활용한 유연하고 훈련이 필요 없는 방법인 WEICOM을 소개한다.