https://arxiv.org/abs/2401.17270
YOLO-World: Real-Time Open-Vocabulary Object Detection
The You Only Look Once (YOLO) series of detectors have established themselves as efficient and practical tools. However, their reliance on predefined and trained object categories limits their applicability in open scenarios. Addressing this limitation, we
arxiv.org

Abstract & Introduction
You Only Look Once(YOLO) 시리즈 검출기는 효율적이고 실용적인 도구이다. 하지만 사전에 정의되고 학습된 객체 카테고리에 의존하기 때문에 open scenarios에서 적용이 제한되는 문제가 있다. 이러한 한계를 해결하기 위해 YOLO-World를 제안한다. 이는 YOLO를 비전-언어 모델링과 대규모 데이터셋 사전 학습을 통해 개방형 어휘 검출 기능으로 강화한 혁신적인 접근 방식이다. 재구성 가능(Re-parameterizable) 비전-언어 경로 집계 네트워크(RepVL-PAN)와 영역-텍스트 대조 손실(region-text contrastive loss)을 도입하여 시각 정보와 언어 정보 간의 상호작용을 촉진한다.
기존 방법들과 비교했을 때 YOLO-World는 높은 추론 속도와 효율적인 배포가 가능하다. 구체적으로 표준 YOLO 아키텍처를 따르며 입력 텍스트를 인코딩하기 위해 사전 학습된 CLIP 텍스트 인코더를 활용한다. 또한, 텍스트와 이미지 특징을 연결하여 시각-의미 표현을 향상시키기 위해 Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) 를 제안한다.
실세계 시나리오에 개방형 어휘 객체 검출의 효율성을 높이기 위해 prompt-then-detect 패러다임을 탐구한다.
(a) Tradition Object Detector : 학습 데이터셋에 의해 고정된 어휘만 검출할 수 있어서 새로운 객체나 개방형 환경에서의 유연성이 떨어진다.
(b) Previous Open-Vocabulary Detector : 사용자의 프롬프트를 텍스트 인코더로 인코딩하여 온라인 어휘를 생성하고 객체를 검출한다. 주로 Swin-L과 같은 대형 백본을 사용하는 대형 검출기를 활용해 개방형 어휘 능력을 확장하려는 경향이 있다. 대형 모델을 사용해 강력한 성능을 보이지만, 이미지와 텍스트를 동시에 인코딩해야 하므로 실시간 적용에서 속도가 느리다.
(c) YOLO-World : 경량 YOLO 모델을 기반으로 하여 효율적인 개방형 어휘 검출을 가능하게 한다. 프롬프트를 사전에 인코딩해 오프라인 어휘로 변환하고, 이를 모델 가중치로 재구성함으로써 추론 속도를 크게 향상시킨다.
주요 기여는 다음 세 가지로 요약된다.
1. 실세계 애플리케이션을 위한 고효율 개방형 어휘 객체 검출기인 YOLO-World
2. 비전과 언어 특징을 연결하기 위한 Re-parameterizable Vision-Language PAN 방식 제안
3. 대규모 데이터셋에서 사전 학습된 YOLO-World는 강력한 제로샷 성능을 보임. 사전 학습된 YOLO-World는 개방형 어휘 인스턴스 분할 및 지시 객체 검출과 같은 다운스트림 작업에도 쉽게 적용
Related works
Open-Vocabulary Object Detection
개방형 어휘 객체 검출 (OVD): 미리 학습되지 않은 새로운 클래스(예: 캥거루, 드론 등)를 탐지할 수 있다. 학습 데이터에 없는 객체들도 텍스트 설명이나 사전 학습된 언어 모델을 활용해 검출할 수 있다.
Method
Pre-trainnig Formulation : Region-Text Pairs
전통적인 객체 탐지 방법은 instance annotation으로 학습된다.
Ω={Bi,ci}Ni=1
- Bi : 바운딩 박스
- ci: 카테고리 레이블
해당 논문에서는 region-text pairs를 reformulate한다.
Ω={Bi,ti}Ni=1
- ti : 카테고리 이름, 명사구, 객체 설명
YOLO-World는 이미지 I와 명사 집합 T를 입력으로 받아 바운딩 박스 B̂k 및 객체 임베딩ek(ek∈RD)을 출력한다.
Model Architecture
YOLO-World의 전체 아키텍처는 YOLO detector, 텍스트 인코더, RepVL-PAN(Re-parameterizable Vision-Language Path Aggregation Network) 로 구성된다.
YOLO Detector
- YOLOv8을 기반 개발
- Darknet 백본을 이미지 인코더로 사용
- PAN으로 다중 스케일 피처 파라미드 생성
- 바운딩 박스 회귀와 객체 임베딩을 위한 헤드 포함
텍스트 인코더
- CLIP으로 사전 학습된 트랜스포머 텍스트 인코더 사용
- 입력 텍스트를 임베딩으로 변환
W=TextEncoder(T)∈RCxD (C : 명사 개수, D : 임베딩 차원)
텍스트 대조 헤드
- 바운딩 박스와 객체 임베딩을 위한 decoupled head를 사용
- L2 정규화와 어파인 변환을 통해 객체-텍스트 유사도 계산
- 객체 임베딩 ek과 텍스트 임베딩 wj 간의 유사도를 계산
sk,j=α⋅L2-Norm(ek)⋅L2-Norm(wj)T+β
Training with Online Vocabulary
- 온라인 어휘 사용
- 모자이크 샘플당 최대 80개의 명사로 구성된 어휘
- 긍정적 명사와 무작위로 선택된 부정적 명사 포함
Inference with Offline Vocabulary
- 오프라인 어휘를 사용하는 prompt-then-detect 전략 사용
- 사용자가 정의한 프롬프트를 미리 인코딩하여 저장
- 실시간 계산 부하를 줄이고 필요에 따라 어휘 조정 가능
Re-parameterizable Vision-Language PAN

RepVL-PAN은 다중 스케일 이미지 특징 C3,C4,C5를 기반으로 피라미드를 구축한다. 이를 통해 다양한 스케일의 이미지를 하나의 모델에서 처리할 수 있다. 또한 텍스트 유도 CSPLayer(T-CSPLayer)와 이미지 풀링 주의(I-Pooling Attention)를 제안하여 시각-언어 상호작용을 강화한다.
* 이미지에서 추출된 다중 해상도 특징 맵 C3,C4,C5
텍스트-지향 CSPLayer
- CSPLayer(교차 단계 부분 레이어)는 상향식 또는 하향식 융합 이후에 사용
- CSPLayer(C2f)를 확장하여 다중 스케일 이미지 특징에 텍스트 지도를 결합
- max-sigmoid attention을 적용하여 텍스트 특징을 이미지 특징에 결합 = 텍스트 정보를 이미지의 각 특징에 가중치를 부여해 결합
- 텍스트 지도를 결합한다 = 텍스트 정보를 이미지 특징에 추가하여 풍부한 정보를 제공
X′l=Xl⋅δ(maxj∈{1..C}(XlWTj))T
이미지 풀링 주의
- 다중 스케일 특징에 대한 3×3 영역의 최대 풀링 적용
- 풀링은 이미지 특징을 압축하는 과정으로, 여기서는 3x3 영역의 최대 풀링을 통해 중요한 정보만 추출
- 27개의 패치 토큰 생성 : 풀링을 통해 이미지 특징을 더 작은 영역(패치)로 나누고 각 패치에서 중요한 특징을 추출
W′=W+MultiHead-Attention(W,X,X′) - 즉, 텍스트 임베딩이 이미지 특징에 의해 갱신되며, 이미지와 텍스트가 서로 영향을 주고받음
Pre-training Schemes
Learning from Region-Text Contrastive Loss
- 작업 정렬 레이블 할당을 통한 예측과 실제 주석 매칭
L(I)=Lcon+λI⋅(Liou+Ldfl) - λ_I는 탐지 데이터일 때 1, 이미지-텍스트 데이터일 때 0
Pseudo Labeling with Image-Text Data
이미지-텍스트 쌍을 직접 사용하기보다는, 우리는 세 가지 단계를 통해 의사 영역-텍스트 쌍을 생성하는 자동 레이블링 방식을 제안한다. 이를 통해 CC3M 데이터셋에서 246k개의 이미지와 821k개의 의사 주석을 레이블링한다.
1. 명사구 추출 : n-그램 알고리즘을 사용해 명사구 추출
2. 의사 레이블링 : 사전 학습된 개방형 어휘 탐지기를 사용해 이미지에 대한 의사 박스를 생성
3. 필터링: CLIP을 활용해 관련성을 평가하고, 비관련성 의사 주석을 필터링
Experiments
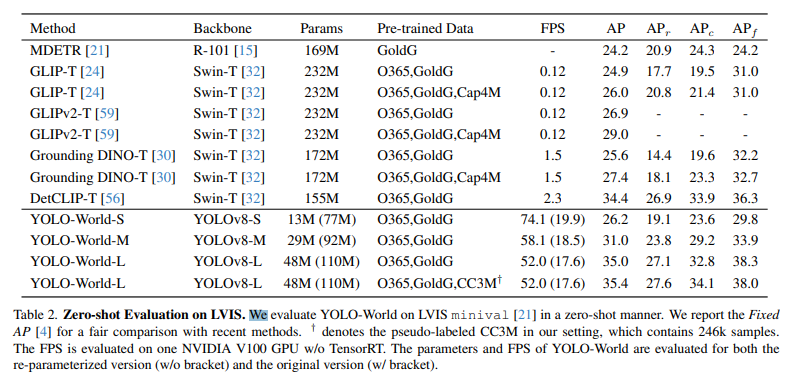
zero shot evaluation
DEMO : https://huggingface.co/spaces/stevengrove/YOLO-World


Conclusion
기존 YOLO를 비전-언어 아키텍처로 재구성하였으며 RepVL-PAN을 통해 비전-언어 정보의 효율적 연결을 진행했다. 작은 모델에서도 비전-언어 사전 학습의 효과성을 확인했으며 효과적인 사전학습 scheme을 제안했다.