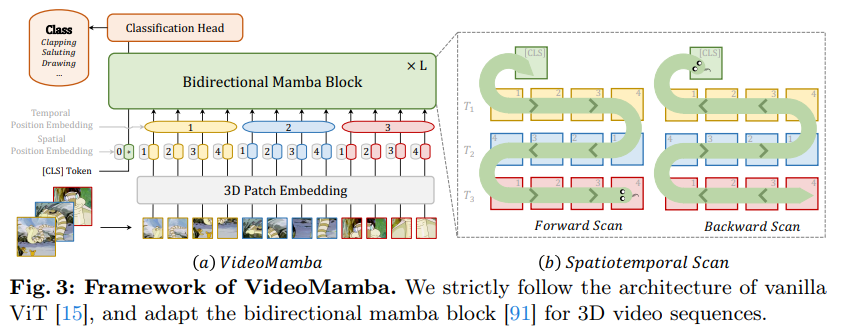
https://arxiv.org/abs/2403.06977 VideoMamba: State Space Model for Efficient Video UnderstandingAddressing the dual challenges of local redundancy and global dependencies in video understanding, this work innovatively adapts the Mamba to the video domain. The proposed VideoMamba overcomes the limitations of existing 3D convolution neural networks andarxiv.org Abstract본 연구는 Mamba 모델을 비디오 도메인에 적용한..