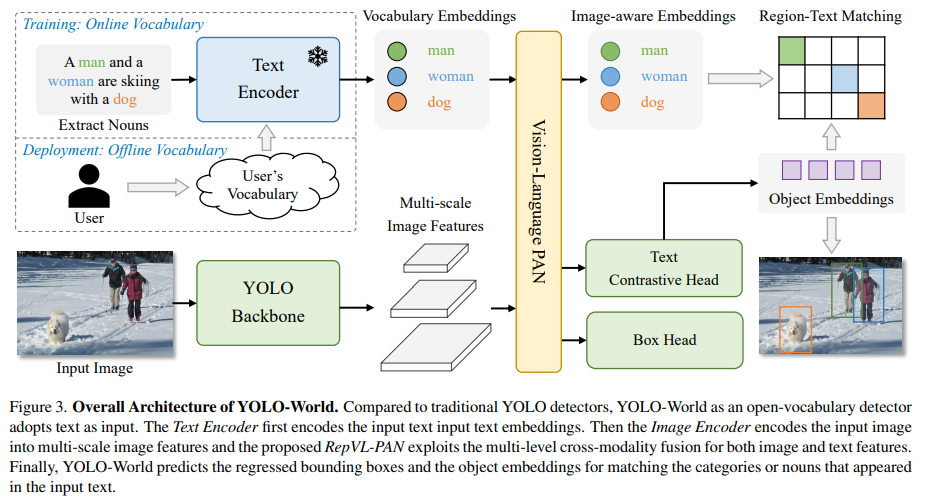
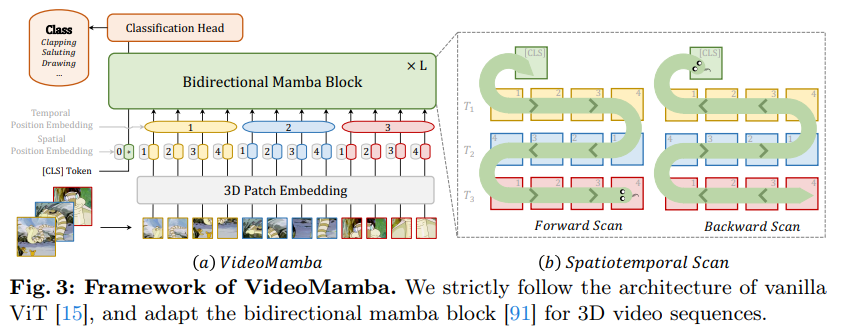
https://arxiv.org/abs/2401.17270 YOLO-World: Real-Time Open-Vocabulary Object DetectionThe You Only Look Once (YOLO) series of detectors have established themselves as efficient and practical tools. However, their reliance on predefined and trained object categories limits their applicability in open scenarios. Addressing this limitation, wearxiv.orgAbstract & IntroductionYou Only Look Once(YOLO..