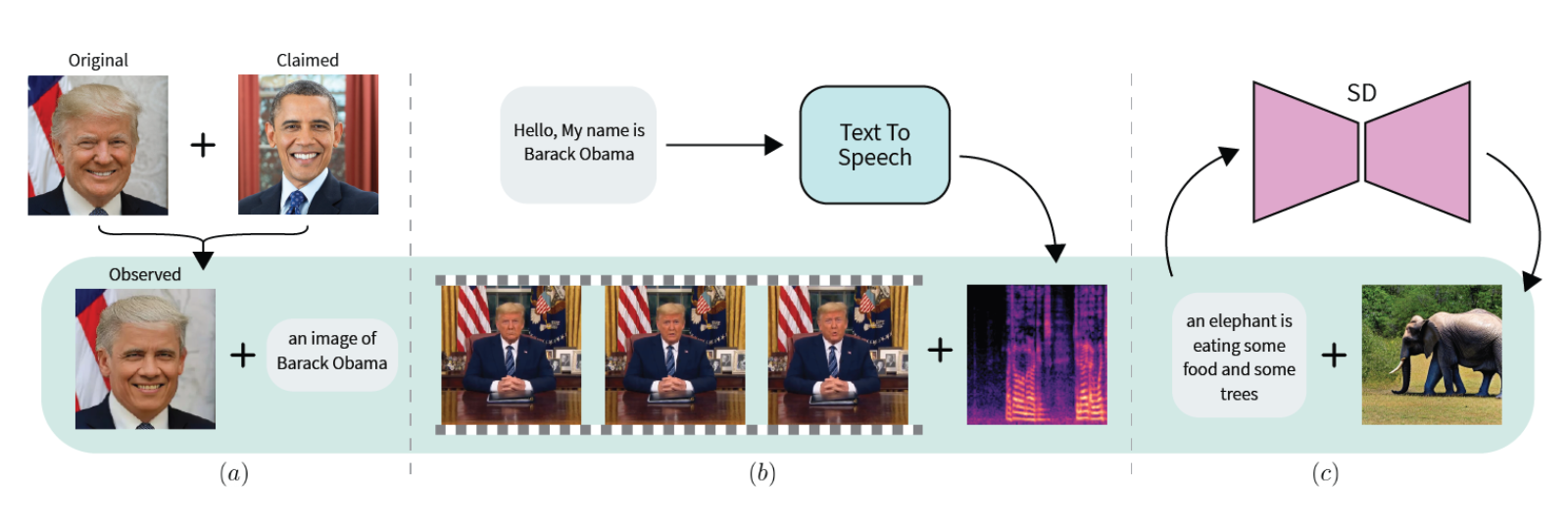
https://arxiv.org/abs/2310.12921 Vision-Language Models are Zero-Shot Reward Models for Reinforcement LearningReinforcement learning (RL) requires either manually specifying a reward function, which is often infeasible, or learning a reward model from a large amount of human feedback, which is often very expensive. We study a more sample-efficient alternative: usiarxiv.org 비전 기반 환경에서 RL을 훈련시키는 데..