https://arxiv.org/abs/2403.06977
VideoMamba: State Space Model for Efficient Video Understanding
Addressing the dual challenges of local redundancy and global dependencies in video understanding, this work innovatively adapts the Mamba to the video domain. The proposed VideoMamba overcomes the limitations of existing 3D convolution neural networks and
arxiv.org
Abstract
본 연구는 Mamba 모델을 비디오 도메인에 적용한 연구이다. VideoMamba는 기존의 3D 컨볼루션 신경망 및 비디오 트랜스포머의 한계를 극복한다. 해당 연구를 통해 네 가지 핵심 능력을 확인할 수 있다.
(1) Scala-bility in the visual domain without extensive dataset pretraining
(2) Sensitivity for recognizing shortterm actions even with fine-grained motion differences
(3) Superiority in long-term video understanding, showcasing significant advancements over traditional feature-based models
(4) Compatibility with other modalities, demonstrating robustness in multi-modal contexts
Introduction
Mamba는 선형 복잡성을 유지하는 SSM 기반의 모델로 장기 동적 모델링에 강점을 보인다. 이러한 특성에 기반해 비디와 같은 더 긴 시퀀스를 생성할 때에도 Mamba가 효과적으로 작동할 수 있을지에 대한 질문이 생긴다.
이를 바탕으로 개발된 VideoMamba는 비디오 시퀀스에서의 공간적 및 시간적 정보를 동시에 고려하여 고해상도 장기 비디오를 효율적으로 처리하는 것을 목표로 한다. VideoMamba는 ViT 스타일을 기본으로 하되, 합성곱과 어텐션의 장점을 결합하여 동적 시공간 모델링에 적합한 선형 복잡도 접근 방식을 제공한다.
이처럼 VideoMamba는 스페이셜 토큰과 템포럴 토큰을 결합하여 비디오 시퀀스를 처리함으로써 기존의 ViT 모델에서 한 단계 더 나아간 성능을 발휘한다.
1. Scalability in the Visual Domain
Mamba 모델은 스케일이 커질수록 과적합 우려가 있지만, self-distillation 전략을 통해 대규모 데이터 없이도 성능이 향상된다.
2. Sensitivity for Short-term Action Recognition
VideoMamba는 작은 움직임 차이를 구별하는 데 탁월하며, 열고 닫기 같은 동작에서 어텐션 기반 모델보다 정확도가 높다.
3. Superiority in Long-term Video Understanding
End-to-end 학습을 통해 VideoMamba는 기존 피처 기반 방식보다 장기 비디오 이해에서 우수한 성능을 보인다.
4. Compatibility with Other Modalities
ViT와 비교하여, VideoMamba는 복잡한 상황에서 다중 모달리티와의 통합이 강하며, 긴 비디오에서도 성능이 개선된다.
Related Works & Preliminaries
State Space Models
SSM은 상태 표현을 설명하고, 입력에 따라 다음 상태가 어떻게 될지 예측하는 모델이다.
1. 상태 방정식 (State Equation)
상태 공간 모델은 시스템의 상태 벡터 $h(t)$가 시간에 따라 변화하는 과정을 설명한다.

- $A$: 시스템의 상태가 시간에 따라 어떻게 변화하는지를 나타내는 매트릭스
- $B$: 입력 $x(t)$가 시스템의 상태에 미치는 영향을 결정하는 매트릭스
- $h(t)$: 시간 $t$에서 시스템의 현재 상태 벡터
2. 출력 방정식 (Output Equation)
시스템의 상태를 바탕으로 관측 가능한 출력 $y(t)$를 계산한다.


- $C$: 은닉 상태 $h(t)$에서 출력 $y(t)$로 변환하는 투영 매트릭스
- $D$: 입력 $x(t)$가 출력에 미치는 영향을 나타내는 스칼라
이로 인해 시스템의 내부 상태 $h(t)$가 출력 $y(t)$로 변환되며, 이를 통해 외부에서 관측할 수 있는 출력을 제공한다.
SSM의 이산화 (Discretization)
연속적인 시스템으로 모델링된 상태 공간 모델은 실제로 이산적인 시간 단계에서 작동해야 한다.
이를 위해 연속 모델을 이산화하여 이산적인 시간 단계에서 모델을 적용할 수 있다.
- 연속 상태 방정식 : $h'(t) = Ah(t) + Bx(t)$
- 이산 상태 방정식 : $h_{k+1} = A_dh_k + B_dx_k$
이산화 과정에서 제로-오더 홀드 (ZOH, Zero-Order Hold) 방식이 자주 사용한다.
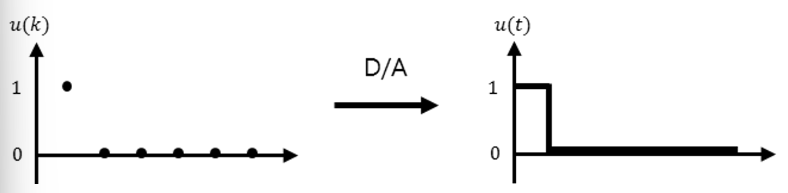
- 이산 신호를 받으면 새로운 이산 신호를 받을 때까지 그 값을 유지
$A_d=e^{AΔt}$로 계산하여 상태 전이 행렬을 얻고, $B_d$는 수식에서 얻은 $A$와 $B$를 이용해 적분을 통해 구한다.
연속적인 상태 공간 모델을 이산 시스템으로 변환하여 실제 구현하도록 만든다.
커널화된 상태 공간 모델 (Kernelized SSM)
상태 공간 모델(SSM)은 선형 시불변 시스템 (LTI, Linear Time-Invariant System) 을 기반으로 한다. LTI 시스템에서는 시스템의 동적 특성이 시간이 지나도 변하지 않으며, 선형적인 특성을 가진다. 즉, SSM의 상태 및 출력 방정식에 등장하는 행렬 $A$, $B$, $C$, $D$는 고정된 값으로, 시간이 지나도 변하지 않는다.
하지만 커널화된 상태 공간 모델은 이러한 선형성의 한계를 넘어, LTI 시스템이 다루기 어려운 비선형성을 효과적으로 모델링할 수 있다. 이를 통해 비선형 시스템을 상태 공간 모델링 방식으로 처리할 수 있다.
Mamba의 Selective Scan Mechanism (S6)

S6 메커니즘은 기존 LTI 시스템이 선형 관계에 의존하는 것과는 다르게 입력 데이터에 따라 매개변수($B$, $C$, $\Delta$)가 동적으로 조정된다. 이를 통해 Mamba는 데이터의 맥락과 상태를 반영할 수 있다.
비전용 양방향 SSM (Vision Mamba) / B-Mamba

기존 Mamba 블록은 1D 시퀀스를 위해 설계되었기 때문에 이미지나 비디오와 같은 2D 또는 3D 데이터에서는 공간적 인식이 부족하다. Vision Mamba는 양방향 Mamba(B-Mamba) 블록을 도입하여 비전 애플리케이션에 필요한 공간적 인식을 강화한다. B-Mamba 블록은 전방향 및 후방향의 SSM 처리를 동시에 수행한다.
Method
VideoMamba
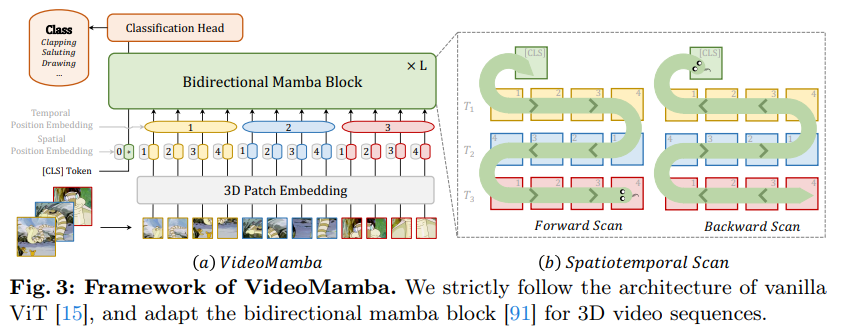
- 3D 컨볼루션을 사용하여 입력 비디오를 공간-시간적 패치로 변환
- 분류 토큰(CLS)과 위치 임베딩을 추가
- B-Mamba 블록을 여러 층 쌓아 처리
- 최종 층의 CLS 토큰을 사용하여 분류 수행
입력 처리
3D 합성곱 (1×16×16 필터 크기)을 사용해 입력 비디오 $X_v \in R^{3×T×H×W}$를 비중첩 spatiotemporal 패치 $X_p \in R^{L×C}$로 투영한다.
- $X_v \in \mathbb{R}^{3 \times T \times H \times W}$ : 입력 비디오
- 3: RGB 채널을 의미 (채널 수)
- $T$: 비디오의 시간 길이 (프레임 수)
- $H$:비디오 프레임의 높이
- $W$: 비디오 프레임의 너비
Spatiotemporal 패치는 비디오 데이터에서 공간적(높이와 너비) 및 시간적(프레임) 정보를 동시에 처리하는 패치이다. 각 패치는 서로 겹치지 않고 독립적인 비중첩(Non-overlapping)으로 존재한다.
- $L$: 패치의 개수
- $C$: 각 패치의 채널 수
최종적으로 비디오 텐서 $X_v$는 $L$개의 비중첩 spatiotemporal 패치로 변환되어 $X_p \in R^{L×C}$ 형태로 입력된다. 각 패치는 시간적, 공간적 정보를 포함하는 고차원 벡터로 변환된다.
토큰 시퀀스 생성
$X = [X_{\text{cls}}, X] + p_s + p_t$
- $X_{\text{cls}}$ :학습 가능한 분류 토큰. 시작 부분에 추가
- $p_s \in \mathbb{R}^{(h w + 1) \times C}$ : 공간 위치 임베딩. 패치들이 원본 이미지나 비디오에서 어느 위치에 있는지를 알려줌
- $p_t \in \mathbb{R}^{t \times C}$ : 시간 위치 임베딩. 각 비디오 프레임이 시간적으로 어떤 순서에 속하는지를 알려줌
spatial 위치 임베딩과 temporal 위치 임베딩을 추가해 토큰의 위치 정보를 모델에 제공함으로써 spatiotemporal 위치 정보를 유지한다.
모델 구조
토큰 $X$는 L개의 B-Mamba 블록을 통해 전달되며, 마지막 층의 [CLS] 토큰 표현은 정규화와 선형 계층을 통해 분류 작업을 수행한다.
Spatiotemporal Scan

B-Mamba 레이어를 시공간 입력에 적용하기 위해, 원래의 2D 스캔을 다양한 양방향 3D 스캔으로 확장한다.
- Spatial-First: 위치에 따라 spatial 토큰을 정리한 후, 프레임 단위로 쌓음
- Temporal-First: 프레임 기반으로 temporal 토큰을 정렬한 후, 공간 차원에서 쌓음
- Spatiotemporal: Spatial-First와 Temporal-First의 혼합으로, v1은 절반만 수행하고 v2는 전체 수행하여 2배의 연산을 수행함
실험 결과 Spatial-First 양방향 스캔이 가장 효과적이면서도 간단한 방식임을 확인할 수 있다.
VideoMamba와 기존 모델 비교
Vim과 비교: VideoMamba는 Vim의 아키텍처를 개선한 것으로, [CLS] 토큰과 로타리 포지션 인코딩(RoPE)을 제거하여 성능을 개선했다. 그 결과, ImageNet-1K에서 더 나은 성능을 보였고, 특히 작은 모델(Vim-Ti)에서 약 0.8% 성능 향상을 보였다.
VMamba와 비교: VideoMamba는 내부 다운샘플링 계층 없이, ViT(Visual Transformer)와 동일한 디자인을 따르며 VMamba보다 효율적이고 과적합 문제를 해결했다. 또한, VideoMamba는 6배 더 빠른 처리 속도와 40배 더 적은 GPU 메모리를 사용하면서 긴 비디오를 효율적으로 처리할 수 있다.
Self-Distillation

큰 Mamba 모델에서 발생하는 과적합을 해결하기 위해 Self-Distillation 기법을 도입하여, 더 작은 모델이 큰 모델의 학습을 돕는 방식으로 과적합(overfitting) 문제를 해결한다.
Masked Modeling
VideoMamba는 처음에 비디오 데이터만 사용하여 학습을 하고, 그 후 텍스트 인코더와 결합하여 이미지-텍스트, 비디오-텍스트 데이터셋에서 학습한다.
- 비디오 데이터에 대한 학습 : VideoMamba는 처음에 비디오 데이터만 사용하여 학습하고, 마스킹되지 않은 비디오 토큰들을 CLIP-ViT 모델의 토큰과 정렬해 비디오의 세부적 시간 정보를 잘 이해하도록 한다.
- 텍스트와의 크로스모달 학습 : 비디오 학습이 끝난 후, VideoMamba는 텍스트 인코더와 결합하여 이미지-텍스트 및 비디오-텍스트 데이터셋을 대상으로 학습한다.
VideoMamba는 SMM(Spatiotemporal Modeling) 특성을 고려하여 토큰 간의 인접성을 유지하는 다양한 마스킹 전략을 도입한다. 기존 방식(UMT)에서 여러 레이어의 출력을 정렬하는 방식이었으나, VideoMamba는 최종 출력만 정렬하면서 계산량을 줄이고 효율성을 높인다.
- UMT(Unified Masked Transformer)에서는 여러 층의 모델에서 출력된 결과를 정렬하여 학습하는 방식
Experiment


Conclusion
VideoMamba는 효율적인 비디오 처리와 시간적, 공간적 정보를 동시에 처리할 수 있도록 설계된 모델이다. Self-Distillation, B-Mamba 블록, Spatiotemporal Scan 등 여러 기법을 통해 VideoMamba는 긴 비디오와 고해상도 비디오를 효율적으로 처리할 수 있으며 비디오와 텍스트의 멀티모달 환경에서도 뛰어난 성능을 보인다.