https://arxiv.org/abs/2408.04145
ComKD-CLIP: Comprehensive Knowledge Distillation for Contrastive Language-Image Pre-traning Model
Contrastive Language-Image Pre-training (CLIP) models excel in integrating semantic information between images and text through contrastive learning techniques. It has achieved remarkable performance in various multimodal tasks. However, the deployment of
arxiv.org
Abstract
본 연구에서는 ComKD-CLIP(Comprehensive Knowledge Distillation for Contrastive Language-Image Pre-traning Model) 대조적 언어-이미지 사전 학습 모델을 위한 포괄적 지식 증류를 제안한다. 크게 두 가지 주요 메커니즘으로 구성된다.
1. Iamge Feature Alignment (IFAlign)
학생 모델이 추출한 이미지 특징을 교사 모델이 추출한 것과 밀접하게 일치하도록 하여, 학생이 이미지 특징을 추출하는 교사 모델의 지식을 학습할 수 있게 한다.
2. Educational Attention (EduAttention)
교사 모델이 추출한 텍스트 특징과 학세 모델이 추출한 이미지 특징 간의 상호 관계를 탐구하여, 학생 모델이 텍스트-이미지 통합 방법을 학습하도록 돕는다.
더불어 교사 모델의 텍스트-이미지 특징 융합 결과를 활용하여 IFAlign과 EduAttention에서 증류된 지식을 세밀하게 다듬어, 학생 모델이 교사의 지식을 정확하게 흡수할 수 있도록 한다.
Introduction

기존의 지식 증류 방법들은 텍스트-이미지 융합의 최종 결과만을 사용하며, 융합 과정에서 내재된 지식을 간과한다.
반면 ComKD-CLIP은 학생 모델이 교사 모델의 지식을 완전히 흡수할 수 있도록 하기 위해, 교사 모델의 특징 융합 과정에서 내재된 지식을 증류하고 교사 모델의 특징 융합 결과를 활용하여 증류된 지식을 정제한다.
IFAlign과 EduAttention 두 가지 주요 모듈로 구성된다.
IFAlign은 학생 모델이 추출한 이미지 특징이 교사 모델이 추출한 것과 밀접하게 일치하도록 하여, 학생이 이미지 특징을 추출하는 교사 모델의 지식을 흡수한다.
EduAttention은 교사 모델이 추출한 텍스트 특징과 학생 모델이 추출한 이미지 특징 간의 상호 관계를 탐구하여 학생 모델이 이미지와 텍스트 특징을 통합하는 교사 모델의 능력을 이해하고 모방하도록 한다.
또한 학생 모델이 교사 모델의 지식을 정확하게 흡수할 수 있도록 증류된 지식을 교사 모델의 특징 융합 결과를 활용하여 정제한다.
주요 기여
- IFAlign 모듈을 제안하여 학생 모델이 텍스트-이미지 특징 융합 과정에서 교사 모델의 이미지 특징 추출 방법을 흡수한다.
- EduAttention 모듈을 제안하여 학생 모델이 텍스트-이미지 특징 융합 과정에서 교사 모델의 텍스트-이미지 통합 방법을 흡수할 수 있게 한다.
- FAlign과 EduAttention에서 증류된 지식을 교사 모델의 특징 융합 결과를 활용하여 정제함으로써, 학생 모델이 교사 모델의 지식을 정확하게 흡수할 수 있게 한다.
Approach
Pipline
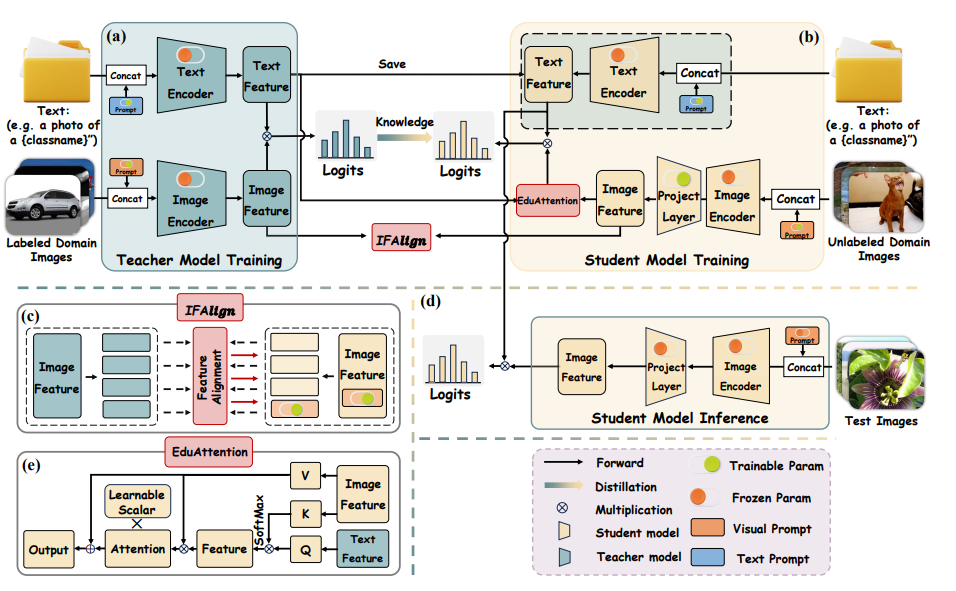
대형 CLIP 교사 모델의 사전 학습
라벨이 있는 도메인 데이터셋 $D_{\text{labeled}} = \{x_i, y_i\}_{i=1}^{M}$를 사용하여 교사 모델을 사전 학습한다. 이 데이터셋에서 이미지와 라벨 쌍이 주어지며, 이는 이미지 인식 작업을 위한 기반이 된다. 추가로 PromptSRC, PromptKD와 같은 최신 방법론을 참고하며, 텍스트와 이미지를 더욱 잘 이해하기 위해 학습 가능한 프롬프트를 도입한다. 이 프롬프트는 교사 모델의 이미지와 텍스트 인코더 분기에 결합된다.
학생 CLIP 모델의 학습
텍스트 인코더의 재사용: 학생 모델은 교사 모델에서 사전 학습된 텍스트 특징을 그대로 재사용함으로써 텍스트 인코더 분기에서 발생하는 추가적인 학습 비용을 대폭 줄인다. 이렇게 하면 텍스트 인코더의 학습을 생략하고도 고품질의 텍스트 특징을 사용할 수 있다.
경량화된 이미지 인코더 설계: 텍스트 인코더 대신, 학생 모델에서는 경량화된 CLIP 이미지 인코더를 설계하여 이미지 특징을 효율적으로 추출한다. 이로써 자원 소모는 줄이면서도 CLIP 모델의 기본적인 성능을 유지할 수 있다.
IFAlign 모듈: 학생 모델에서 이미지 데이터를 처리할 때, IFAlign 모듈을 도입하여 교사 모델의 이미지 특징 $u^t_p \in \mathbb{R}^d$와 학생 모델에서 추출된 이미지 특징 $u^s_p \in \mathbb{R}^d$을 정렬한다. 이를 통해 학생 모델은 교사 모델이 이미지 특징을 어떻게 추출하는지를 배울 수 있으며, 그에 맞춰 자신의 이미지 인코더를 조정하게 된다.
EduAttention 모듈: 이미지와 텍스트 특징 간의 교차 관계를 학습하기 위해, EduAttention 모듈이 도입된다. 이 모듈은 학생 모델에서 추출된 이미지 특징과 교사 모델이 제공한 텍스트 특징 간의 상호작용을 탐색하며, 교사 모델이 두 모달리티를 어떻게 통합하는지에 대한 정보를 학생 모델이 배울 수 있도록 돕는다.
KL 발산 손실을 통한 지식 증류: 마지막으로, 교사 모델과 학생 모델의 로짓 간의 차이를 최소화하기 위해 KL 발산 손실을 사용한다. 이를 통해 교사 모델의 지식이 학생 모델에 효과적으로 증류되며, 학생 모델이 교사 모델의 예측 능력을 정확하게 모방할 수 있도록 한다.
ComKD-CLIP
IFAlign
학생 모델이 추출한 이미지 특징이 교사 모델이 추출한 것과 긴밀히 일치하도록 하기 위해, 추출된 특징의 평균과 분산 통계를 정렬한다.

여기서 $u_s^p$와 $u_t^p$는 각각 학생 모델과 교사 모델이 추출한 이미지 특징을 나타내며,$P(·)$는 학생 모델의 이미지 인코더 분기에서 학습 가능한 투사기를 의미한다.
정렬을 위해 L1 손실을 사용하여 학생 모델과 교사 모델의 평균 및 분산 차이를 최소화한다.
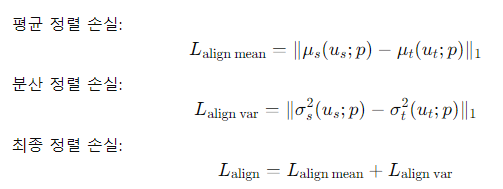
EduAttention
학생 모델이 추출한 이미지 특징과 교사 모델이 제공한 텍스트 특징 간의 교차 관계를 탐색하여 학생 모델이 교사 모델이 사용하는 텍스트-이미지 통합 전략을 학습하도록 돕는다.
이미지 특징($u_s^p$)와 텍스트 특징($w_t^p$)을 사용하여 attention을 계산한다. 기서 $F C(·)$는 완전 연결 층을 나타내며, $Q,K,V$는 각각 쿼리, 키, 값으로 사용된다.

$f_{\text{att}}$는 학생 모델의 이미지 특징과 교사 모델의 텍스트 특징 간의 교차 관계를 나타낸다.
IFAlign과 EduAttention 모듈을 통해 교사 모델로부터 흡수한 지식을 통합하기 위해, $f_{\text{att}}$ 에 학습 가능한 파라미터 $\alpha$를 곱하고, 이미지 특징 $u_s^p$와 요소별로 더하는 방식으로 최종 이미지 특징 $f_e$를 계산한다.
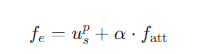
Distilled Knowledge Refinement
KL 발산: 학생 모델이 교사 모델의 이미지 특징 추출 방식과 텍스트-이미지 통합 전략을 학습한 후, KL 발산을 사용하여 두 모델의 로짓 분포 간의 차이를 최소화한다.

여기서 $q_t$와 $q_s$는 각각 교사와 학생 모델이 예측한 로짓을 나타내며, $\tau$는 분포의 매끄러움을 조절하는 온도 매개변수이다.

학생 모델의 정렬 손실 $L_{\text{align}}$과 로짓 분포 간의 차이를 최소화하는 손실 $L_{\text{stu}}$를 결합하여 최종 손실 함수를 정의한다.
정리하면 IFAlign은 이미지 특징의 평균과 분산을 정렬하여 교사 모델의 특징 추출 방식을 학습하고 EduAttention은 텍스트-이미지 관계를 탐색하여 학생 모델이 교사 모델의 통합 전략을 흡수하도록 돕는다. 마지막으로, KL 발산을 통해 교사와 학생 모델 간의 출력 분포 차이를 최소화하여 학생 모델의 성능을 극대화한다.
https://harim061.tistory.com/15
CLIP-KD: An Empirical Study of CLIP Model Distillation
https://arxiv.org/abs/2307.12732 CLIP-KD: An Empirical Study of CLIP Model DistillationContrastive Language-Image Pre-training (CLIP) has become a promising language-supervised visual pre-training framework. This paper aims to distill small CLIP models su
harim061.tistory.com
ComKD-CLIP vs CLIP-KD
- ComKD-CLIP : 주요 초점은 학생 모델이 교사 모델의 이미지 특징을 정렬하고, 텍스트-이미지 통합 방식을 배우는 것
- CLIP-KD : 대조 학습(Contrastive Learning)과 다양한 증류 방법을 결합하여, 학생 모델이 교사 모델의 임베딩 관계와 특성뿐만 아니라 그래디언트 정보까지 학습하도록 하는 데 중점
증류 전략의 다양성
- ComKD-CLIP은 특성 정렬(IFAlign)과 주의 메커니즘(EduAttention)에 집중하여 학생 모델이 교사 모델의 이미지와 텍스트 특징 정렬에 주로 초점
- CLIP-KD는 대조적 관계 증류(CRD)를 포함해 다양한 증류 전략을 제안하며, 임베딩, 그래디언트, 마스킹 등을 통한 여러 경로로 지식을 전달
대조 학습의 강조
- ComKD-CLIP에서는 주로 텍스트-이미지 관계와 특징 정렬을 강조하는 반면, CLIP-KD는 대조적 관계 증류(CRD)를 통해 임베딩 관계를 더 중점적으
- CLIP-KD는 학생 모델이 교사의 대조적 임베딩 구조를 모방하게 하여, 임베딩 품질을 높이는 것이 주요 목적
증류 방법의 깊이
- ComKD-CLIP은 주로 평균-분산 정렬과 주의 메커니즘을 이용한 상호 관계 학습에 중점을 두며, 간결한 증류 방법을 사용
- CLIP-KD는 Feature Distillation, Gradient Distillation, Masked Feature Distillation 등 다양한 증류 방식을 도입해 다양한 지식 전달 경로를 제안