https://arxiv.org/abs/2307.12732
CLIP-KD: An Empirical Study of CLIP Model Distillation
Contrastive Language-Image Pre-training (CLIP) has become a promising language-supervised visual pre-training framework. This paper aims to distill small CLIP models supervised by a large teacher CLIP model. We propose several distillation strategies, incl
arxiv.org
Abstract
본 연구는 CLIP 모델을 더 작은 학생 모델로 증류하는 방법을 제안한다.
그 중에서도 특성 모방과 평균 제곱 오차 손실을 사용하는 방법이 효과적이라는 것을 발견했다.
또한 교사와 학생 인코더 간의 interactive contrastive learning 도 성능 향상에 효과적임을 확인했다.
CLIP-KD의 성공 요인은 교사와 학생 간의 특성 유사성을 극대화하는 데 있었다.
Introduction
CLIP-KD는 사전 학습된 대형 CLIP 모델을 교사로 삼아, 더 작은 학생 CLIP 모델을 증류하여 성능을 향상시킨다.
기존 TinyCLIP과 달리 CLIP-KD는 교사와 학생 모델이 같은 아키텍처를 사용할 필요가 없다.
모방과 상호작용의 관점에서 증류 전략을 설계한다.
모방 학습의 경우 교사가 생성한 해당 지식을 학생이 맞추도록 유도한다. 이는 KD의 기본 프레임워크가 된다.
CLIP을 기반으로 이미지-텍스트 관계, 이미지-텍스트 특성, 기울기를 모방 대상으로 설정한다.
상호 학습의 경우 교사와 학생을 결합하여 공동 대조 학습을 수행하고 학생이 교사로부터 암묵적으로 학습할 수 있도록 한다. 예를 들어 학생은 교사 임베딩과 대조하는 기준점으로 간주된다.
모방 학습 (Mimicry Learning)
학생 모델이 교사 모델이 생성한 지식을 모방하도록 유도함
CLIP의 이미지-텍스트 관계, 이미지-텍스트 특성, 기울기를 모방 대상으로 설정
상호 학습 (Interactive Learning)
교사와 학생 모델을 함께 학습시키며, 학생이 교사로부터 암묵적으로 배우도록 하는 대조 학습 방법\
학생은 교사 임베딩을 기준으로 학습하며, 학생과 교사의 특성을 결합하여 CLIP 학습을 수행
본 연구에서 특성 모방과 평균 제곱 오차 (MSE) 손실이 최고의 성능을 달성함을 확인했으며 상호 대조 학습이 두 번째로 좋은 성능임을 확인했다.
즉 증류 성능이 교사와 학생 간의 특성 유사성이 얼마나 극대화되는지에 따라 달라진다는 것을 발견했으며 이것이 다양한 KD 방법이 서로 다른 성능을 보이는 이유를 설명한다.
주요 기여
1. 관계, 특성, 기울기, 대조적 패러다임을 포함한 증류 전략을 제안 (모방 학습)
2. 본 논문에서 제안하는 증류 방법이 교사와 학생 모델 간의 특성 유사성을 극대화할 수 있음 (상호 학습)
3. CLIP-KD는 아키텍처에 의존하지 않고 일관된 성능 향상을 제공
Methodology

CLIP Knowledge Distillation

CLIP의 핵심 아이디어는 이미지-텍스트 임베딩 싼 간의 유사성을 최대화하는 것이다.
이를 바탕으로, CLIP. 모델 증류의 한 방법으로 대조적 관계 증류 (Contrastive Relational Distillation, CRD) 를 제안한다. CRD는 교사잘 구조화된 임베딩 관계를 학생 모델이 모방하도록 유도하여, 학생 모델의 임베딩 품질을 높인다.
1. 이미지-텍스트 분포

2. 텍스트-이미지 분호

3. KL-발산 손실
- 이미지-텍스트 손실: $L_{CRD}^{I \to T}$
- 텍스트-이미지 손실: $L_{CRD}^{T \to I}$
4. 총 손실
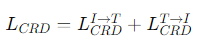
Feature Distillation

특징 증류(Feature Distillation)는 교사와 학생 모델 간의 임베딩 차이를 줄이기 위한 간단한 방법이다.
교사와 학생의 시각 및 텍스트 임베딩이 동일한 공간에서 정렬되도록 MSE 손실을 통해 학습이 이루어지고
임베딩 차원이 다를 경우 Linear Projection을 적용한다.

Masked Feature Distillation

마스킹된 특징 증류(Masked Feature Distillation, MFD)는 교사 모델이 제공하는 정보를 기반으로, 학생이 마스킹된 이미지를 통해 시각적 의미를 복원하는 방식이다. 교사 모델이 마스킹된 영역을 복구하는 데 필요한 중요한 정보를 학생에게 제공하며 이를 통해 학생 모델은 교사의 임베딩 구조를 모방한다.
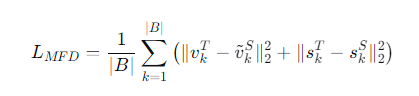
Gradient Distillation

그래디언트 증류(Gradient Distillation)는 학생 모델이 교사 모델의 그래디언트 정보를 학습하도록 돕는다. 학생 모델이 교사와 비슷한 방식으로 입력 변화에 반응하도록 유도하기 위해 그래디언트 정보를 일치시키며, 이를 통해 모델의 성능을 향상시킨다. MSE 손실을 통해 교사와 학생 간의 그래디언트 정보를 정렬한다.

Interactive Contrastive Learning

상호작용 대조 학습(ICL)은 학생 모델과 교사 모델 간의 상호작용을 강화하여, 학생이 교사로부터 더 많은 지식을 학습하도록 돕는 대조 학습 방법이다. 학생을 기준으로 하여 교사의 임베딩을 대조한다.



$L_{ICL}$을 최소하하는 것이 교사와 학생 네트워크 간 상호 정보의 하한을 최대화하는 것과 관련이 있다.
상호 정보는 학생 네트워크의 앵커 임베딩을 알 때 교사 네트워크의 대조 임베딩에서 불확실성을 얼마나 줄일 수 있는지를 측정한다.
즉, 학생 임베딩을 기준으로 교사의 텍스트 임베딩과 이미지를 대조하여 학습이 이루어지며, 이를 통해 상호 정보량을 최대화하여 더 나은 특징 표현을 학습한다
상호 정보는 두 개의 변수(여기서는 학생과 교사의 임베딩)가 서로 얼마나 많은 정보를 공유하고 있는지를 나타낸다. 즉, 하나의 임베딩을 알고 있을 때, 다른 임베딩에 대한 불확실성을 얼마나 줄일 수 있는지를 말한다.
상호 정보는 학생 모델과 교사 모델이 얼마나 비슷하게 학습되고 있는지를 측정하는 기준이다. 예를 들어, 학생의 이미지 임베딩을 알고 있을 때, 교사의 텍스트 임베딩에 대해 얼마나 많은 정보를 얻을 수 있느냐를 나타낸다.
상호 정보의 하한을 최대화한다는 것은 학생과 교사 모델이 서로 유사한 방식으로 데이터를 표현할 수 있도록 만들어주는 것을 의미한다. 학생이 교사의 임베딩을 완벽하게 모방할 수 있다면 이 값은 커지게 된다.
$L_{ICL}$을 최소화하면 학생과 교사 모델이 같은 정보를 더 효율적으로 공유하게 되어 상호 정보가 최대화된다.
Augmented Feature Distillation

증강된 특징 증류(Augmented Feature Distillation)는 교사와 학생의 임베딩을 결합하여 더 나은 학습을 유도한다. 학생 모델이 교사 모델의 임베딩을 통해 의미 있는 임베딩 공간을 형성하도록 도움을 주는 방식으로, 교사 임베딩을 사용하여 학생 임베딩을 증강한다.
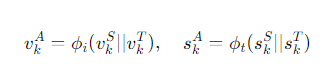
Overall Loss of CLIP Distillation.

최종 loss는 위의 수식과 같다.
Experiments