https://arxiv.org/pdf/2402.02651
본 논문에서는 Vision-Language Model(VLM)을 강화 학습(RL) 에이전트의 표현 학습에 활용하는 PR2L(Promptable Representations for Reinforcement Learning) 프레임워크를 제안한다. PR2L은 VLM이 제공하는 프롬프트 기반 표현을 활용하여, 시각적 관찰로부터 의미론적 특징(Semantic Features)을 추출하고 이를 RL 정책 학습에 적용하는 방식이다. 특히, PR2L은 프롬프팅을 통해 의미론적으로 풍부한 표현을 만들고, 이를 통해 에이전트가 배경 지식을 활용하여 빠르게 행동을 학습할 수 있도록 돕는다.

PR2L - Promptable Representations for Reinforcement Learning
1. 프롬프트 설계
RL 태스크와 관련된 컨텍스트 정보를 담은 프롬프트를 설계하여, VLM이 태스크와 관련된 특징을 효과적으로 추출하도록 유도한다. 예를 들어, "마인크래프트에서 거미는 검은색입니다. 이 이미지에 거미가 있습니까?"와 같은 질의를 통해 특정 개체의 존재 여부를 확인할 수 있다.
- Chain-of-Thought (CoT) 프롬프팅 : VLM이 추론 과정을 설명하도록 유도하여 표현의 의미론적 풍부함을 증가시킨다. 예: "변기가 여기에 있을까요? 왜 그런가요?"
- 프롬프트 평가 : 작은 데이터셋에서 VLM의 응답이 실제 라벨과 얼마나 일치하는지 평가(True Positive/Negative Rate)하여, downstream RL 성능을 간접적으로 측정한다.

2. VLM을 이용한 표현 추출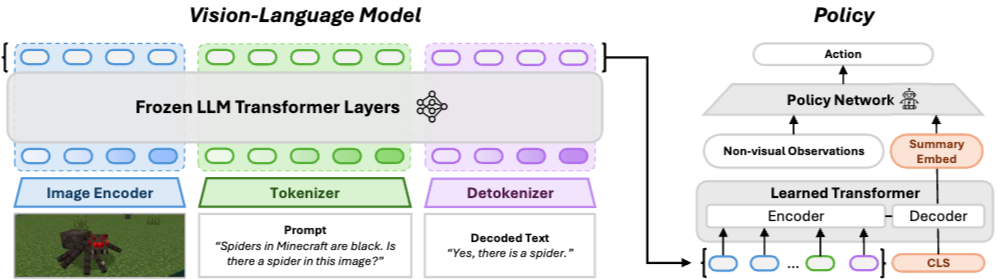
설계된 프롬프트와 에이전트가 관찰한 시각적 관찰 데이터를 VLM에 입력하여 표현을 추출한다.
- Image Encoder : 마인크래프트의 거미 이미지를 입력받아 시각적 특징을 추출한다
- Tokenizer : 텍스트 프롬프트("마인크래프트의 거미는 검은색입니다. 이 이미지에 거미가 있습니까?")를 토큰으로 분할한다
- Frozen LLM Transformer Layers : 이미지 특징과 텍스트 토큰을 처리하여 의미 있는 표현을 생성한다. 이때, LLM은 사전 훈련된 상태로 고정되어 있다
- Detokenizer : Transformer Layers에서 생성된 토큰을 다시 텍스트로 변환한다
- Decoded Text : 디코딩된 텍스트 결과("네, 거미가 있습니다.")를 출력한다. 이 텍스트는 버려지지만, 이 텍스트를 생성하는 과정에서 VLM 내부의 표현(embeddings)이 생성된다
VLM이 생성한 텍스트 응답은 버리고, 대신 Transformer 레이어에서 생성된 토큰 임베딩(Token Embedding)을 추출하여 표현으로 사용한다. $\rightarrow$ 에이전트의 상태를 나타내는 입력으로 정책 네트워크에 전달
CoT 프롬프팅을 통해 생성된 텍스트 응답을 직접 사용하는 것이 아니라, 그 응답을 만들어내는 과정에서 VLM이 생성한 embeddings을 활용한다. VLM이 생성하는 텍스트가 항상 정확하거나 신뢰할 수 있는 정보를 담고 있다고 보장할 수 없기에 토큰 임베딩만 사용한다.
- VLM 모델 : InstructBLIP과 Prismatic VLM을 사용
- InstructBLIP : instruction-tuning을 적용하여 다양한 vision-language 태스크에서 높은 성능을 발휘하는 모델
- Prismatic VLM : 시각적 조건을 기반으로 언어 모델의 표현력을 확장하는 데 초점을 맞춘 모델
- Semantic Features : 이미지나 텍스트에서 의미론적으로 중요한 정보를 추출하는 과정으로, 객체 인식 및 관계 파악 등에 활용될 수 있다
3. 정책 학습
추출된 표현을 RL 정책 학습의 입력으로 사용하여 최적의 행동을 학습한다. 프롬프트 가능한 표현과 비시각적 관찰 정보가 입력으로 들어간다.
- Learned Transformer: VLM에서 생성된 임베딩과 추가적인 비 시각적 관측 정보를 입력받아 요약된 표현(Summary Embed)을 생성한다
- Encoder: VLM에서 생성된 variable-length VLM representations를 고정된 크기의 벡터로 압축한다
- Decoder: CLS(classification) 토큰을 이용하여 모든 입력을 요약한다
- Non-visual Observations : 시각 정보 외의 다른 정보(예: 에이전트의 위치, 속도 등)를 나타낸다
- Policy Network : 요약된 표현(Summary Embed)과 비 시각적 관측 정보를 기반으로 행동(Action)을 결정한다
- 정책 학습 알고리즘
- PPO(Proximal Policy Optimization)
- CQL(Conservative Q-Learning)
- Transformer 기반 정책 네트워크
- 가변 길이 시퀀스인 VLM 표현을 단일 벡터로 압축하기 위해 Transformer 레이어를 포함
- 학습 가능한 CLS(classification) 토큰을 사용하여 입력을 요약(Summary Embed 생성)
Experiments

- VLM 비프롬프트 방식 : ViT-g/14 이미지 인코더 사용, 프롬프트 없이 활용
- VLM 직접 행동 출력 방식 : Brohan et al.(2023) 방식 차용, RL로 행동 보정
- 픽셀 기반 모델 기반 RL : Dreamer v3 사용
- 사전 훈련된 Embodied Control 모델 : VC-1, R3M 비교
- Minecraft 데이터 기반 사전 훈련 모델 : MineCLIP, VPT, STEVE-1

- PR2L 두 가지 버전 : CoT(Chain-of-Thought) 사용 여부 실험
- VLM 이미지 인코더 사용 모델 : Dino+SigLIP 기반
- VC-1 비교 : CLS 토큰 vs. Transformer 기반 요약 모델
- 훈련 데이터 : 전체 데이터셋(77k 트레젝토리)의 1/10만 사용

Habitat 환경에서 VLM(Vision-Language Model)이 프롬프트에 응답하는 예시이다.
- 프롬프트의 목적 : "Would a [target] be found here? Why or why not?" 형태의 질문을 통해 VLM이 특정 객체(target)가 주어진 장소에 있을 가능성을 판단하고 그 이유를 설명하도록 유도
- VLM 응답 분석
- 화장실 (Toilet): VLM은 화장실이 침실에는 없고, 화장실에 있을 것이라고 응답. 이는 VLM이 장소에 따른 객체의 일반적인 위치에 대한 지식을 가지고 있음을 보임
- 침대 (Bed) : VLM은 침대가 식당에는 없고, 침실에 있을 것이라고 응답. 이는 VLM이 가구와 방의 기능 간의 관계를 이해하고 있음을 나타냄
- 소파 (Sofa) : VLM은 소파가 부엌에는 없고, 거실에 있을 것이라고 응답. 이는 VLM이 특정 가구가 주로 어떤 공간에 배치되는지에 대한 지식을 가지고 있음을 보여줌
- 색상 강조
- 초록색 : VLM이 이미지에서 관찰한 내용
- 파란색 : VLM이 일반적인 지식 또는 규칙을 언급
- 빨간색 : VLM이 객체의 존재를 명시적으로 확인