https://arxiv.org/abs/2211.01335
chinese clip paper review
언어 특화된 모델을 특정 시나리오에 특화되도록 transfer하는 것은 힘든 과정입니다. 따라서 해당 논문은 2개의 pretrainig method를 제안합니다.

Chinese CLIP은 Open AI CLIP과 같은 아키텍처를 가지게 됩니다. 다만 Locked-Image Tuning(LiT)을 통해서만 학습하면 언어의 specific 도메인에서 이미지 정보를 충분히 학습하지 못하게 됩니다. 따라서 Chinese CLIP은 두 단계의 pretrainig method를 가집니다.
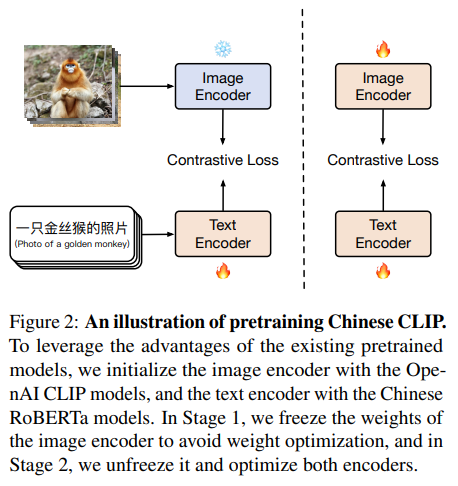
1단계 : LiT 기반의 사전 학습
- 목표 : 텍스트 인코더가 중국어 데이터에 적응하도록 지원합니다.
- 방법
- 이미지 인코더는 동결(freeze) 상태로 유지합니다.
- 텍스트 인코더만 LiT 방법을 통해 최적화합니다.
- 진행 기준 : 텍스트 인코더의 성능이 하위 작업(다운스트림 작업)에서 뚜렷한 성능 개선을 보일 때까지 계속합니다. 즉, 텍스트 인코더가 비전-언어 정렬을 잘 수행하며, 더 이상의 성능 향상이 기대되지 않을 때까지 진행합니다.
2단계 : 대조 튜닝 (Contrastive Tuning)
- 목표 : 이미지와 텍스트 간의 관계를 학습하여 모델의 성능을 향상시킵니다.
- 방법
- 이미지 인코더와 텍스트 인코더 모두를 대조 튜닝 기법으로 학습합니다.
- 모두 매개변수가 최적화됩니다.
첫 단계에서는 LiT 방법으로 기존 모델의 비전 인코더에서 고품질의 표현을 읽어낼 수 있도록 텍스트 인코더를 학습합니다. 두 번째 단계에서는 전체 모델을 중국어 데이터의 도메인으로 전이하여 효과적인 학습을 달성합니다. 두 단계의 사전 학습 방법은 처음부터 사전 학습을 하거나 사전 학습된 모델에서 직접 미세 조정하는 것보다 더 나은 성능을 발휘합니다.

즉, 이 방식으로 Chinese CLIP 모델은 LiT 방법으로 기존 모델의 장점을 활용하고, 대조 튜닝을 통해 언어-specific 데이터를 효과적으로 전이할 수 있습니다.
