1. 트랜스포머의 한계
- 트랜스포머(Transformer) 모델은 특히 셀프 어텐션(self-attention) 메커니즘으로 인해 매우 강력하지만, 그 계산 복잡도가 제곱형(quadratic)으로 증가하여 연산량이 많고 처리 속도가 느리다는 한계가 있음
- 이로 인해 트랜스포머 모델은 대규모 데이터 처리에 비효율적
2. Mamba 모델
- Mamba 모델을 포함한 선택적 상태 공간 모델(SSM)은 이러한 트랜스포머의 한계를 극복하기 위한 대안으로 등장
- Mamba 모델은 선형적인 시간 복잡도를 가지며, 트랜스포머에 비해 더 나은 스케일링 성능을 보임
3. Mamba 모델의 한계
- 사전 정의된 객체 카테고리에 대해 고정된 방식으로 학습하기 때문에 제로샷 학습(새로운 클래스에 대해 추가 학습 없이 예측하는 능력)에서 트랜스포머에 비해 성능이 떨어짐
- Mamba 모델이 특정 범주의 데이터에 대해서만 강력하지만, 새로운 데이터에 대해서는 일반화가 어렵다는 문제
4. 해결 방안 : 대규모 언어-이미지 통합
- 대규모 언어-이미지 통합 사전 훈련이 필요하다고 논문은 제안
- CLIP 모델의 사전 훈련 파이프라인을 Mamba 모델에 적용
- 이미지와 텍스트가 같은 벡터 공간에서 의미적으로 가까운 위치를 가지도록 학습합
5. CLIP-Mamba 모델의 기여
- Mamba 모델에 CLIP(Contrastive Language-Image Pretraining) 사전 훈련을 적용하여 제로샷 학습 성능을 향상시키려는 시도
- 결과적으로, 소규모 파라미터로도 더 큰 트랜스포머 모델을 능가하는 성능을 보여주며, OOD(Out-of-Distribution) 데이터에 대한 일반화 성능에서도 우수함을 입증
- Hessian 분석을 통해 Mamba 모델의 훈련 경사(Training Landscape)가 더 비볼록하고 날카로운 경향을 보인다는 점을 밝혀냄
convexity
- 손실 함수 또는 목적 함수의 모양과 관련이 있음
- 볼록 함수 : 함수의 모든 접선이 함수의 그래프 위에 있거나, 함수와 접하는 지점만 그래프에 접함
- 비볼록 함수 : 하나 이상의 국소 최적값을 가짐
볼록 함수는 국소 최적값(local minimum)이 곧 전역 최적값(global minimum)으로 이어짐 > 기울기 하강법을 사용하면 최적해 찾기 쉬움
비볼록 함수는 여러 개의 국소 최적값이 존재해 최적화가 어려움 > 기울기 하강법을 사용할 떄, 국소 최적값에 빠질 위험 존
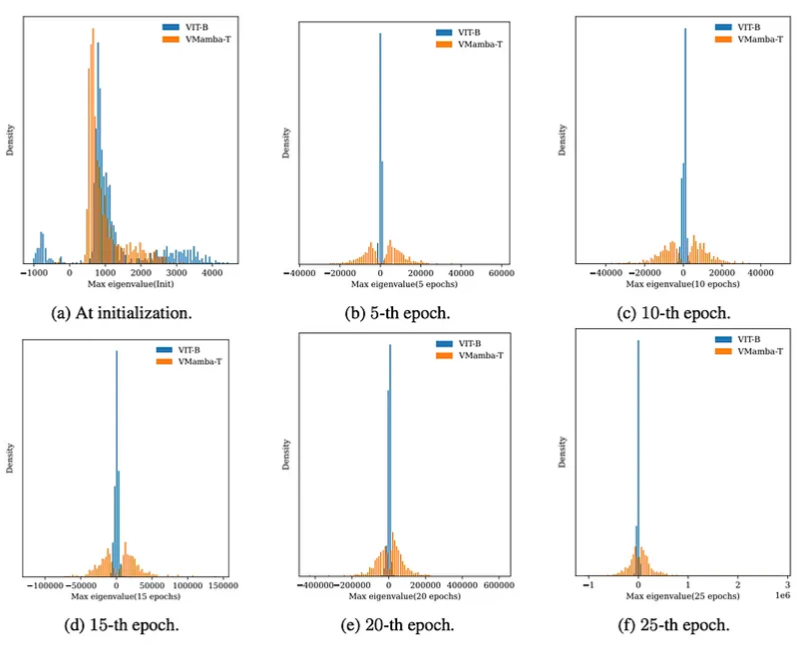
- Mamba 모델의 훈련 경가사 더 비볼록하다는 것은 Mamba 모델의 손실 함수가 여러 국소 최적값을 가지고 있어 최적화 과정이 더 복잡하고 어려움