https://www.youtube.com/watch?v=3Ch14GDY5Y8&list=PL_iJu012NOxehE8fdF9me4TLfbdv3ZW8g&index=2
Reinforcement learning = 맛집 찾기!
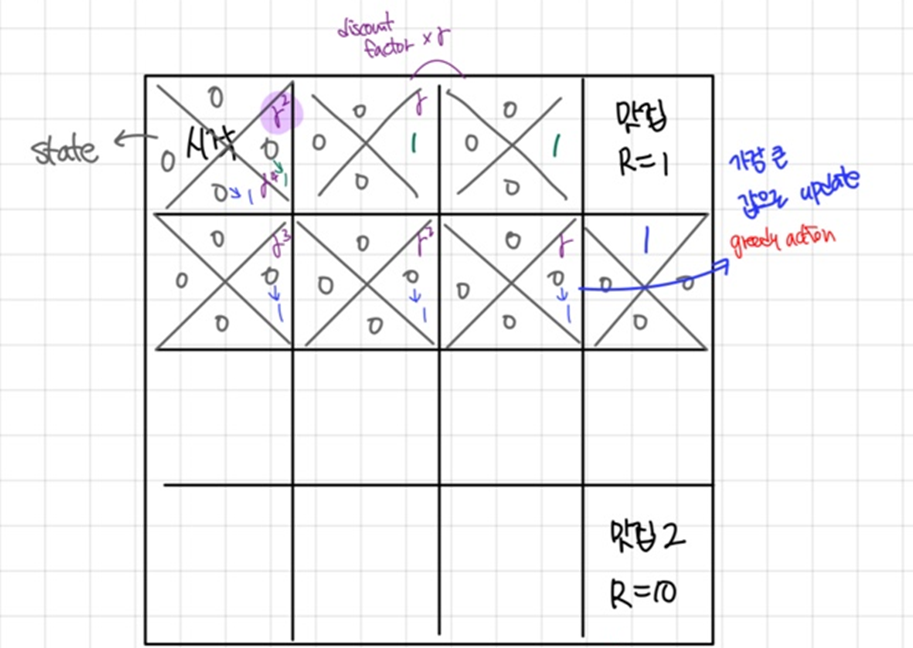
Q-learning
상태(state)와 행동(action)의 조합에 따른 보상(reward)을 학습하여 최적의 행동 정책(policy)을 수립한다. 각 행동에 대해 예상되는 점수(q)를 계산하고 점수가 가장 높은 행동을 선택한다.
Greedy action
항상 현재 상태에서 가장 높은 점수를 가진 행동을 선택하는 전략이다.
Exploration (탐험)
장점 1. 새로운 path를 발견할 수 있다.
장점 2. 새로운 맛집을 발견할 가능성을 제공한다.
> 탐험만 한다면 효율적인 학습이 어려우므로 Exploration과 Exploitation을 균형 있게 조절해야 한다.
Exploration & Exploitation
Exploitation : 현재까지 학습된 정보를 바탕으로 최적이라고 판단되는 행동을 선택
Exploration : 새로운 행동을 시도하여 추가 정보를 얻음
ε - Greedy
ε의 확률로 랜덤하게 행동을 선택하고, 나머지 확률(1-ε)로 최적 행동(Greedy Action)을 선택한다. (ε : 0~1 사이의 값)
(Decaying) ε - Greedy
학습 초기에는 Exploration을 많이 하다가 점차 학습이 진행될수록 비율을 줄이고 Exploitation을 늘린다.
Discount factor
현재의 보상과 미래의 보상 간의 중요도를 조정하는 역할을 한다.
γ = 0에 가까울수록 현재의 보상을 더 중요시하고, γ = 1에 가까울수록 미래의 보상도 동일하게 고려한다.
(γ : 0~1 사이의 값)
- γ = 0 : \( R + 0 \times \max_{a'} Q(s', a') = R \)
→ 미래 보상은 아예 무시하고, 즉시 보상만 고려한다.
- γ = 1: \( R + 1 \times \max_{a'} Q(s', a') \)
→ 현재 보상과 미래 보상을 동일하게 중요시한다.
장점 1. 장기적인 보상을 고려하므로 효율적인 path이다.
장점 2. 현재 vs 미래 reward
Q - update
$$Q(s,a) \leftarrow Q(s, a) + \alpha[R + \gamma \max_{a'} Q(s', a')]$$
- : 현재 상태 에서 행동 를 선택했을 때의 점수
- α (학습률) : 새로운 정보를 얼마나 받아들일지 결정
- R : 현재 행동에 대한 즉각적인 보상
- γ : 미래 보상의 중요도를 결정하는 감가율
'강화학습' 카테고리의 다른 글
| [강화학습] 3-2강. Monte Carlo (MC) 방법 (1) | 2025.01.08 |
|---|---|
| [강화학습] 3-1강. Optimal policy (0) | 2025.01.08 |
| [강화학습] 2-3강. 벨만 방정식 (Bellman equation) (0) | 2025.01.08 |
| [강화학습] 2-2강. 상태 가치 함수 V & 행동 가치 함수 Q & Optimal policy (0) | 2025.01.05 |
| [강화학습] 2-1강. Markov Decision Process (MDP) (1) | 2025.01.05 |