[논문리뷰] Recurrent neural network based language model
https://www.fit.vut.cz/research/group/speech/public/publi/2010/mikolov_interspeech2010_IS100722.pdf
Abstract
순환 신경망(Recurrent neural network based language model)이 제안되었으며 해당 모델은 음성 인식에 응용될 수 있다. 백오프 언어 모델에 비해 perplexity를 50% 줄일 수 있으며, 음성 인식 실험에서는 동일한 데이터 양으로 학습된 모델을 비교할 때 단어 오류율이 약 18% 감소했다.
Introduction
statistical language modeling의 목표는 주어진 문맥에서 데이터의 다음 단어를 예측하는 것이다. 따라서 언어 모델을 구축할 때 순차 데이터 예측 문제를 다루게 된다. 가장 널리 사용된 n-gram statistic은 언어를 단어라는 atomic 시퀀스로 간주하며 이 단어들이 문장을 구성하고 문장의 끝 기호가 중요한 역할을 한다고 가정한다. 하지만 연구에서 제안된 복잡한 모델은 적은 학습 데이터에만 효과적이며, 실제 사용 사례에서 거의 채택되지 않는다.
Model description
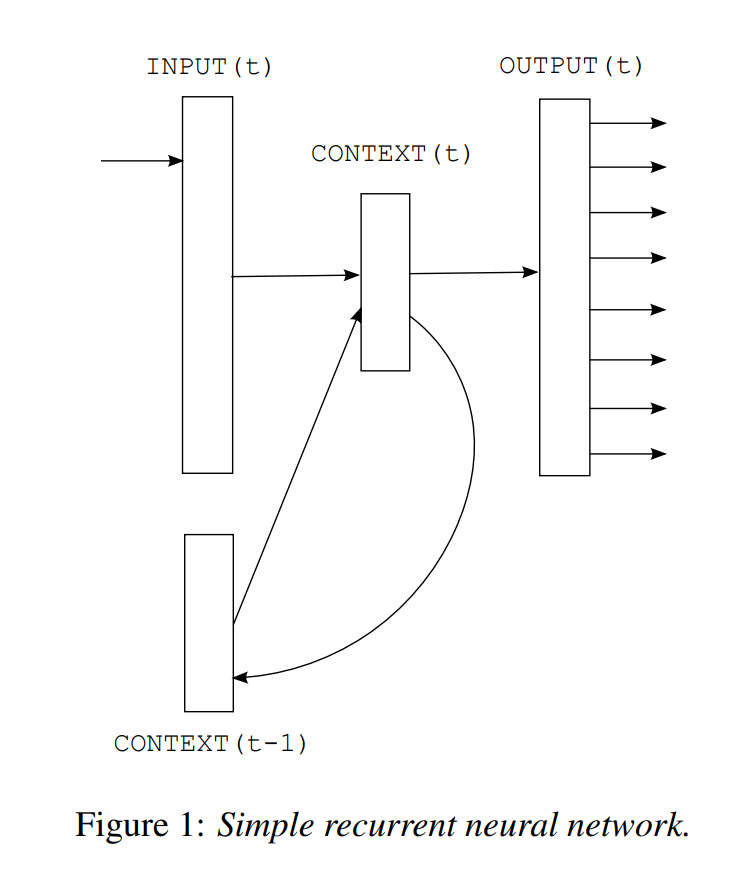
Bengio의 feedforward 신경망 모델은 고정된 문맥 길이를 사용하여 문맥 활용이 제한적이다. RNN은 재귀 연결을 통해 정보를 네트워크 내에서 순환시켜 임의 길이의 문맥을 암묵적으로 인코딩한다. 학습 과정에서 장기 의존성을 학습하는 데 어려움이 있을 수 있다. 따라서 본 논문에서는 simple recurrent neural network 또는 Elman network를 사용한다.
간단한 RNN 구조로 input layer ($x$), hidden layer ($s$), output layer ($y$)로 이루어져있다.
$$x(t) = w(t) + s(t-1)$$
Input vector $x(t)$는 현재 단어 vector $w$와 이전 문맥층 $s(t-1)$을 결합한 벡터이다. 즉, 현재 입력과 이전 상태를 결합하여 새로운 상태를 생성한다.
$$s_j(t)= f\left(\sum_{i} x_i(t) u_{ji}\right)$$
$$y_k(t)= g\left(\sum_{j} s_j(t) v_{kj}\right)$$
hidden layer는 sigmoid 함수, output layer는 softmax 함수를 통해 계산한다.
초기화 이후 단계에서 $s(t+1)$은 $s(t)$의 복사본으로 설정된다. 입력 벡터 $x(t)$는 시간 $t$에서 1-of-N 인코딩으로 표현된 단어와 이전 문맥 층으로 구성된다. (벡터 $x$의 크게 = 어휘 크기 $V$ + 문맥 층 크기)
훈련 과정에서 역전파 알고리즘과 SGD로 학습을 진행하여 각 epoch 후, 검증 데이터에서 log-likelihood를 측정한 후 개선이 없으면 학습률 $\alpha$를 절반으로 줄이고 개선되면 학습을 지속한다. 따라서 대규모 은닉층을 사용하더라도 네트워크가 과적합되지 않는다.
출력층 $y(t)$는 이전 단어 $w(t)$와 문맥 $s(t-1)$에 기반하여 다음 단어의 확률 분포를 표현한다. softmax 함수를 통해 다음 조건을 만족한다. :
- 모든 $y_m(t) > 0 $ (모든 단어에 대해 확률은 양수)
- 확률 분포의 합이 1)
오차는 cross 엔트로피 기준으로 오차 벡터를 계산한다.
$$error(t) = desired(t) - y(t)$$
- : 1-of-N 인코딩으로 표현된, 특정 문맥에서 예측해야 할 단어
- $y(t)$ : 네트워크의 실제 출력값
테스트 중에는 모델이 데이터 처리를 진행하면서 업데이트되지 않는다. 테스트 데이터에서 고유명사가 반복적으로 등장해도 낮은 확률을 가지게 된다. 따라서 synapses 가중치에 장기 기억이 있어야함을 시사한다. 테스트 중에도 학습을 지속하는 모델을 동적(dynamic) 모델이라고 부른다. 고정된 학습률 $\alpha = 0.1$을 사용하고 훈련 시 모든 데이터를 여러 epoch에 걸쳐 학습하지만 테스트 시에는 데이터를 단 한 번만 처리하며 업데이트한다. 동적 모델은 기존 cache 기법과 유사하나 continuous space에서 학습한다는 점이 차이가 있다. 예를 들어 'dog'와 'cat'이 관계가 있다면, 테스트 데이터에서 'dog'가 빈번히 등장하면 'cat'의 확률도 증가한다. 따라서 동적 업데이트를 통해 새로운 도메인에 자동으로 적응 가능하다. RNN은 은닉층 크기만 조정하고 피드포워드 신경망보다 간단하게 설정 가능하다.
cache 모델
최근 관찰된 데이터를 기반으로 확률 분포를 동적으로 조정하는 방법이다. 최근에 등장한 단어나 상태의 출현 빈도를 기반으로 예측한다. 예를 들어 "dog"가 최근 많이 등장했다면 "dog"와 관련된 단어("bark", "cat")의 확률을 높인다.
Optimization
성능 향상을 위해 훈련 텍스트에서 특정 기준보다 적게 등장한 단어를 모드 하나의 rare token으로 병합한다.
$$P(w_i(t+1)|w(t), s(t-1)) = \begin{cases}y_{\text{rare}}(t) \cdot C_{\text{rare}}, & \text{if } w_i(t+1) \text{ is rare} \\ y_i(t), & \text{otherwise} \end{cases}$$
- $y_{\text{rare}}(t)$ : 희귀 토큰의 출력 확률
- $C_{\text{rare}}$ : 주어진 기준보다 적게 등장한 단어 수
희귀 단어는 모두 동일하게 취급되며, 이들 사이 확률은 균등하게 분포된다.
WSJ experiments
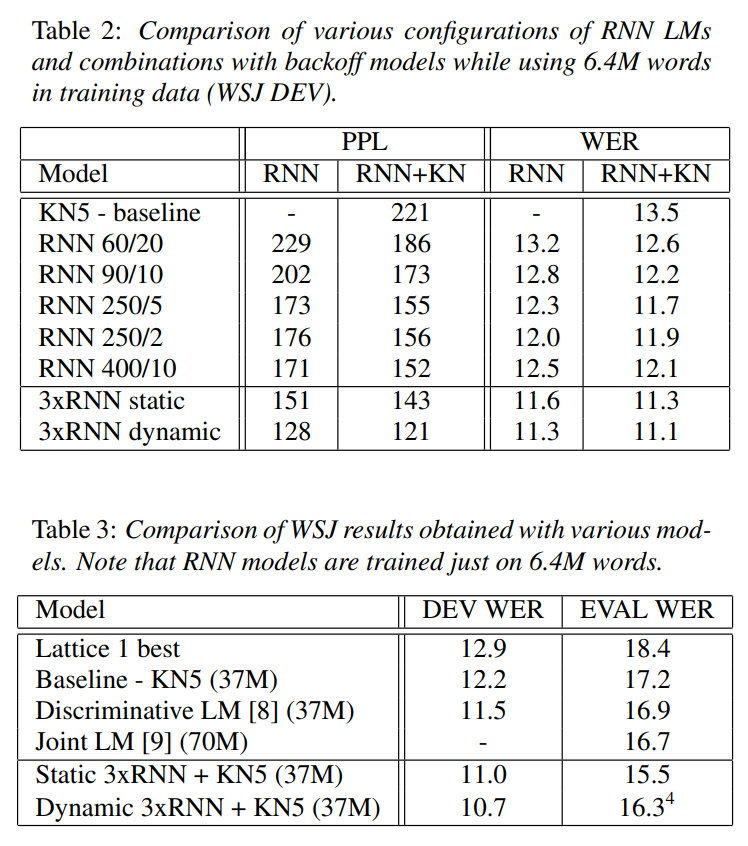
Dynamic 3xRNN은 WER 및 PPL에서 가장 뛰어난 성능을 보인다. PPL은 최대 50% 감소했으며 WER은 최대 12% 개선했다. 제한된 데이터와 자원으로도 RNN 기반 모델이 기존 Backoff 모델 대비 우수한 성능을 발휘했다.
Conclusion
RNN은 이전 시점의 출력 또는 상태(hidden state)를 현재 입력과 결합해 다음 출력을 생성한다. Backpropagation Through Time을 사용해 학습하며 시간 축으로 펼쳐진 RNN의 그래프에서 모든 시점의 에러를 역전파하며 가중치를 업데이트한다. 또한 동적 모델링(온라인 학습) 기법으로 테스트 중에도 네트워크를 업데이트하며 변화하는 데이터에 적응한다.